Keycloak’da Token Mapper’ları İnceleyelim… #11
Merhaba,
Bu içeriğimizde, Keycloak’da üretilen token’ların içine ek veri eklenmesini sağlayan Token Mapper mekanizmasını mercek altına alıyor olacak ve nedir, ne işe yarar ve hangi senaryolarda kullanılır? gibi sorulara cevap ararken, konuyu sadece teoride bırakmayıp pratik örneklerle de pekiştirerek adım adım inceliyor olacağız. Evet, hazırsanız başlayabiliriz…
Token Mapper Nedir?
Token Mapper, Keycloak’un token issuance (token üretme) sürecinde kullanıcı bilgilerini, rollerini, grup bilgilerini, session notlarını vs. access token, ID token ve UserInfo endpoint gibi OIDC token’larına eklememizi sağlayan oldukça kullanışlı ve kritik bir mekanizmadır.
Token Mapper’lar ile kullanıcıdan gelen veri token’daki bir claim haline getirilmekte, yani “Token’ın içine ne koyayım?” sorusunun cevabı verilmektedir…
Ne Amaca Hizmet Etmektedir?
Token Mapper, Keycloak’ta oluşturulan token’ların içine varsayılan olarak gelen kullanıcı id, username ve süre gibi temel bilgilerin ötesine geçerek, gerçek hayatta ihtiyaç duyulan rol, yetki, departman, özel alanlar veya dış sistemlerden gelen verileri eklemeye yaramaktadır. Yani sistemdeki farklı veri kaynaklarından belirli bilgileri alıp bunları token içinde anlamlı claim’ler olarak yerleştirir ve böylece API’lerin veya uygulamaların ekstra bir sorguya ihtiyaç duymadan bu bilgilere doğrudan token üzerinden erişmesini sağlar.
Bir token’ın geçerli olup olmadığını ve içeriğini auth server’a sorarak öğrenme yöntemidir.
JWT hızlıdır ama eski veriye sahip olabilir. Ancak introspection yavaş olsa da her zaman doğru veriyi getirecektir.
Bunu şöyle örneklendirebiliriz;
Token bir kere, değiştirilemez şekilde oluşturulur. Misal olarak ‘admin’ rolüne sahip bir kullanıcıya token üretildiğinde bu token’a role: admin claim’i eklenecektir. Kullanıcıdan bu rol alınsa dahi ilgili token ömrünün sonuna kadar o yetkiye sahip olacaktır. Ancak introspection’da ise her istekte gidip en güncel durum elde edilecek ve kullanıcı ‘admin’ değilse bu o anda fark edilecektir!
Token Mapper, token içeriğinin uygulamanın ihtiyaçlarına göre esnek biçimde şekillendirilmesini sağlayarak sadece gerekli verilerin eklenmesini ve gereksiz ya da hassas bilgilerin dışarıda bırakılmasını mümkün kılmaktadır. Bu sayede hem güvenlik hem de token boyutu optimize edilirken; sub, name, email, roles gibi standart claim’ler dahil edilebilir ya da tamamen ihtiyaca özel custom claim’ler üretilebilir. Ayrıca farklı client’lar için farklı claim set’leri tanımlanarak her uygulamanın yalnızca kendi ihtiyaç duyduğu veriyi alması da sağlanabilir. Bunun yanında kullanıcıya gösterilecek bilgilerin consent ekranlarında kontrol edilmesine imkan tanır ve lightweight access token, token exchange veya introspection gibi ileri seviye kimlik doğrulama ve yetkilendirme senaryolarıyla da uyumlu çalışarak sistemin hem esnek hem de ölçeklenebilir olmasına katkı sağlayabilir.
Mapper’lar Nerelerde Kullanılır?
- Authorization (Yetkilendirme) Süreçlerinde
Authorization senaryolarında token mapper kullanımı, kullanıcı sisteme giriş yaptığı taktirde sahip olduğu rol ve izinlerin (örneğinadminrolü ya daread,writegibi yetkiler) token içine eklenmesi ve API’nin her istekte bu bilgileri okuyarak karar vermesi mantığına dayanmaktadır. Yani API ekstra bir veritabanı sorgusu yapmaksızın, sadece token içindekiroleveyapermissionsgibi claim’lere bakarak kullanıcının belirli bir işlemi yapmaya yetkisi olup olmadığını hızlı ve doğrudan kontrol edebilir. - Microservice Mimarisinde
Microservice mimarisinde her servisin kullanıcı bilgisi için ayrı ayrı veritabanına gitmesini engellemek amacıyla kullanıcı adı, rolü veyahut farklı özellikleri gibi gerek duyulan kullanıcı verileri token içerisine token mapper’lar aracılığıyla önceden eklenerek tüm servislerin bu bilgileri doğrudan token üzerinden okuması sağlanıp oldukça hızlı ve bağımsız bir çalışma sergilenebilir. - External Sistem Entegrasyonunda
External sistem entegrasyonu bağlamında token mapper kullanımı, kullanıcıya ait bilgilerin sadece Keycloak içinden değil, LDAP, veritabanı veya başka bir özel kaynaktan alınarak token içine eklenmesini ifade etmektedir. Yani, kullanıcıya ait bir attribute dış bir sistemde tutuluyor olsa bile, bu bilgi login sırasında çekilip token’a yerleştirilir ve böylece uygulamalar bu veriye doğrudan token üzerinden erişebilir, ekstra bir entegrasyon çağrısı yapma ihtiyacı ortadan kalkar. - Frontend Kullanımında
Frontend kullanımında token mapper ise kullanıcı giriş yaptıktan sonra gerekli bazı bilgilerin (örneğin kullanıcı adı, rol veya feature flag gibi verilerin) token içine eklenmesini sağlayarak frontend uygulamasının bu bilgilere ekstradan bir API çağrısı yapmadan doğrudan token üzerinden ulaşmasını sağlamakta ve böylece hem performansı artırmakta hem de uygulamanın daha hızlı ve bağımsız çalışmasına imkan tanımaktadır.
Mapper’lar Nasıl Çalışır?
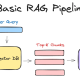
Token mapper’lar, token üretim pipeline’ının bir parçasıdır.
 Token mapper’ların çalışma mantığı yukarıdaki görseldeki gibidir… Burada tek dikkat edilmesi gereken 2. adım olan bilgi toplama aşamasıdır. Evet… Keycloak, token üretmeden önce aşağıdaki bilgileri toplamaya koyulmaktadır:
Token mapper’ların çalışma mantığı yukarıdaki görseldeki gibidir… Burada tek dikkat edilmesi gereken 2. adım olan bilgi toplama aşamasıdır. Evet… Keycloak, token üretmeden önce aşağıdaki bilgileri toplamaya koyulmaktadır:
- User Bilgileri
- id
- username
- attributes
- roles
- Client Bilgileri
- hangi uygulama istek attı?
- bu client’ın mapper’ları nelerdir?
- hangi scope’lar bağlı?
- Realm Bilgileri
- global ayarlar
- default scope’lar
- realm-level roller
Ardından sistemdeki tüm mapper’ları toplayarak, bu bilgiler eşliğinde bu mapper’ları çalıştıracaktır.
Mapper veri üretmez, var olan veriyi taşır / dönüştürür.
Mapper Türleri Nelerdir?
Şimdi gelin en önemli mapper türlerine dair farkındalık oluşturalım…
| Mapper Türü | Açıklama | Örnek |
|---|---|---|
| User Attribute | Keycloak’da bir kullanıcının sahip olduğu ek bilgileri (attribute’ları) alıp token içine eklemeye yarayan bir mapper türüdür. Örneğin; kullanıcı profilinde tanımlı olan department = IT gibi bir değeri, bu mapper sayesinde token oluşturma sürecinde uygun bir claim olarak token’a yerleştirebilir ve nihai olarak üretilen token içinde örnekte verildiği şekilde okunabilir bir değer üretilebilir. Böylece API’lerden yahut frontend’den ekstra bir sorgu yapmaksızın bu bilgiye doğrudan token üzerinden erişilebilir. |
{
"department": "IT"
}
|
| Role Mapper | Keycloak’da kullanıcının sahip olduğu rolleri alıp token içerisine claim olarak ekleyen bir mapper türüdür. Yani kullanıcıya atanmış olan ‘admin’ veya ‘user’ gibi roller, token oluşturulurken otomatik olarak toplanır ve örnekteki şekilde token içine yerleştirilebilir. Bu vesileyle API veya uygulama tarafı yine ek bir sorguya ihtiyaç duymaksızın kullanıcının yetkilerini doğrudan token üzerinden okuyabilir ve hatta bu değerlere göre authorization işlemlerini de gerçekleştirebilir. |
{
"roles": ["admin","user"]
}
|
| Hardcoded | Hardcoded mapper, Keycloak’da herhangi bir veri kaynağına ihtiyaç duymaksızın token içerisine sabit (statik) bir değer eklenmesine yaramaktadır. Kullanıcıya veya role bağlı olmaksızın önceden belirlenen bir bilgiyi her token oluşturulduğunda otomatik olarak içine yerleştirir. |
{
"app": "mobile"
}
|
| Group Mapper | Kullanıcının dahil olduğu grupları alarak bunları token içerisine claim olarak ekleyen bir mapper türüdür. Kullanıcı hangi gruplara üyeyse bu bilgiler token oluşturulurken toplanır ve örnekteki şekilde token içerisine yerleştirilir. Böylece uygulamalar kullanıcının grup bazlı yetkilerini doğrudan token üzerinden edinebilme şansı elde etmiş olur. |
{
"groups": ["admin-group"]
}
|
| Script Mapper | Script mapper, yukarıdaki standart mapper’ların sunduğu sabit ve doğrudan veri taşıma mantığının ötesine geçerek JavaScript tabanlı özel bir mantık çalıştırılmasına imkan veren gelişmiş bir mapper türüdür. Bu mapper ile kullanıcıya ait rol, attribute veya diğer bilgiler üzerinde işlem yapılabilir, bunlar birleştirilebilir ya da belirli koşullara göre yeni claim’ler üretilebilir. Misal olarak kullanıcı rolü ‘admin’ ise token içerisine permission = full gibi dinamik bir değer eklenerek daha esnek ve senaryoya özel bir yapı kurulabilir. |
{
"permission": "full"
}
|
Token Mapper’ların İç Yapısı
Mimarisel olarak her bir mapper, token’a claim eklemeyi sağlayan birer plugin’dir.
Bir mapper’ın iç yapısında aşağıdaki gibi dört ana husus söz konusudur;
- Yapılandırma: Keycloak dashboard’da görülen alanlar yapılandırma kapsamında değerlendirilir. Bu aşamada kurgulanan yapılandırma sayesinde runtime’da mapper’a nasıl davranacağı söylenir.
- Veri Kaynağı: Mapper’ın beslendiği kaynaklardır. Mapper, -veriyi nereden alacağım?- sorusuna buradan cevap bulacaktır.
- Dönüştürme (Mapping Logic): Mapper’ın kaynaktan elde ettiği veriyi claim formatına dönüştürmesidir.
- Token’a Entekte Etme: Nihai olarak elde edilen veri token içerisine yerleştirilir.
Token Mapper’ları Kullanırken Nelere Dikkat Edilmelidir?
Token mapper’larda olay sadece ‘claim eklemek’ değildir! Esasında performans, güvenlik ve mimarisel dengeyi doğru kurgulamak gerekmektedir! Keycloak’u kullanan çoğu sistemin bu noktada hata yaptığını söyleyebilirim. Haliyle bu açıdan olayı değerlendirdiğimizde sahada en ideal olabilecek yaklaşım için dikkat edilmesi gereken noktalara temas etmekte fayda görmekteyim…
- Token gereksiz yere şişirilmemelidir!
Token mapper kullanırken en kritik noktalardan biri token’ın gereksiz verilerle lüzumsuz yere şişirilmemesine özen gösterilmesidir. Çünkü, JWT her istekte client ile server arasında taşınacaktır. Ee bu durumda her fazladan verinin ağ trafiğine maliyet olarak yansıyacağı anlamına gelmektedir. Bu durum, özellikle mobil veya düşük bant genişliğine sahip ortamlarda ciddi performans problemlerine yol açabilir. Bu yüzden en doğru yaklaşım, her istekte sadece gerçekten ihtiyaç duyulan minimum bilginin token içerisine konulmasıdır. - Token’a hassas veriler koyulmamalıdır!
Token mapper kullanırken dikkat edilmesi gereken en önemli konulardan biri de hassas verilerin token içine konulmamasına dikkat edilmesidir. Malumunuz, JWT yapısal olarak sadece base64 ile encode edilir ve aslında şifrelenmemektedir! Yani token’ı ele geçiren herkes çok kolay bir şekilde decode ederek içeriğini okuyabilir! Bu nedenle TCKN, gereksiz e-posta bilgileri yahut özel kullanıcı verileri gibi hassas bilgiler token içine eklenmemelidir. - Access Token ile ID Token ayrımı gerçekleştirilmelidir!
Token mapper kullanırken en sık yapılan olası hatalardan biri de Access Token ile ID Token ayrımının gözetilmemesidir! Access Token, aslında API’lerin kullanması ve yetkilendirme gibi backend taraflı kontrollerin sağlanması için tasarlanmışken, ID Token ise genellikle frontend uygulamalarının kullanıcıya ait bilgilere erişebilmesi için tasarlanmıştır. Bu teorik ayrımdan yola çıkarak rol ve yetki gibi authorization sürecini ilgilendiren veriler Access Token içerisinde yer almalıyken; kullanıcı adı, anasının kızlık soyadı vs. gibi frontend’in ilgileneceği veriler ise ID Token’da bulunmalıdır. - Token’ın değiştirilemez (immutable) olduğu unutulmamalıdır!
Token mapper kullanırken gözden kaçırılmaması gereken bir diğer nokta ise token’ın değiştirilemez (immutable) olmasıdır. Yani kullanıcıya ait bir rol veya yetki değiştiğinde daha önce üretilmiş token’lar bu değişiklikten etkilenmeyecek ve eski bilgileri taşımaya devam edecektir! Bu durum, zaman zaman sistemde istemsizce tutarsızlıklara yol açabilecektir. İşte bundan kaynaklı bu durumu yönetebilmek adına token sürelerini kısa tutmalı ve mümkünse refresh token mekanizmasıyla süreç desteklenerek gerektiği taktirde kullanıcıyı sistemden düşürüp (revoke/logout) yeni token alması sağlanmalıdır. Bu ve buna benzer stratejilerle süreç daha korunaklı ve güvenilir hale getirilmelidir. - Script mapper’lar dikkatli kullanılmalıdır!
Script mapper’lar oldukça güçlü olmalarına rağmen beraberinde kritik riskler barındırmaktadırlar. Bu mapper’lar JavaScript tabanlı özel logic çalıştırdığı için her token üretiminde ekstra işlem yükü oluşturabilir ve bu da özellikle yoğun sistemlerde performans düşüşüne neden olabilir. Ayrıca bu tür dinamik yapıların debug edilmesi zor olduğu için bakım maliyetlerinin yüksek hale gelebilme olasılığı söz konusudur. Bu yüzden, Script mapper’ların yalnızca standart mapper’ların yeterli olmadığı ve gerçekten özel bir iş kuralına ihtiyaç duyulduğu durumlarda tercih edilmesine özen gösterilmelidir. - Claim isimlendirme standardına özen gösterilmelidir!
Gelişi güzel veya belirsiz isimler kullanmak zamanla sistemde ciddi bir karmaşaya yol açabilir. Bu her konuda geçerli olduğu gibi claim’ler için de geçerlidir. Neyi temsil ettiği belli olmayan alanlar yerine açık ve anlamlı isimler tercih edilmeli ve mümkün mertebecamelCaseyahutsnake_casegibi isimlendirme standardı benimsenmelidir. Ve daha da önemlisi OpenID Connect (OIDC) tarafından zaten tanımlanmış standart claim isimleri mevcutsa bunlara sadık kalınmalıdır. - Yerine göre client scope kullanılmalıdır!
Token mapper kullanımında yapılan bir diğer hata ise bir mapper’ı birden fazla client için tekrar tekrar tanımlamaktır. Bu yaklaşım, kısa vadede çalışsa da uzun vadede ciddi bir yönetim ve bakım karmaşasına yol açacaktır. Çünkü, herhangi bir değişiklik gerektiğinde tüm client’larda tek tek güncelleme yapmak gerekecektir. Bunun yerine Keycloak’ta Client Scope kullanarak mapper’ları merkezi bir yapıya almak çok daha doğru bir yaklaşım olacaktır. Böylece ilgili mapper’ı bir kez tanımlayabilir ve ihtiyaç duyulan tüm client’lara bu scope’u bağlayarak hem tekrarın önüne geçilebilir hem de daha temiz, sürdürülebilir ve ölçeklenebilir bir yapı kurulabilir. - Gereksiz mapper yazmaktan çekinilmelidir!
Her mapper, uygulamanın login ve authentication süreçlerinde ekstra bir katman olarak devreye girecektir. Bu da her istekte ek işlem, bellek kullanımı ve CPU maliyeti anlamına gelir. Özellikle birden fazla mapper kullandığınızda bu etki katlanarak büyüyebilir ve auth işlemlerinde belirgin şekilde yavaşlama söz konusu olabilir. Bu yüzden prensip çok nettir! Mümkün olduğunca az ve gerçekten gerekliyse mapper yazılmalıdır… - Token boyutu test edilmelidir!
JWT token boyutu, çoğu geliştiricinin göz ardı ettiği ama performans açısından oldukça kritik bir konudur. Token ne kadar büyükse, her HTTP isteğinin header’ında o kadar fazla veri taşınacak, bu da ağ trafiğini şişirecek ve latency’yi artıracaktır. Bundan kaynaklı token’ın kaç KB olduğu mutlaka test edilmeli ve header size’ı ölçülmelidir. İdeal olarak token boyutunu mümkün mertebe 2-3 KB’ın altında tutmaktır. Bu kontrol performans optimizasyonunun bir parçasıdır. - Microservice uyumu düşünülmelidir!
Mapper’ı tasarlarken en önemli sorulardan biri -bu veri gerçekten tüm microservice’lerde lazım mı?- sorusudur… Eğer cevap evet ise, yani veri birçok servisin ortak ihtiyacıysa, o taktirde token’a koymakta fayda olacaktır. Yok eğer birkaç servise özgü bir veri ise token’ı şişirmek yerine o verinin o servislere özel olarak başka şekillerde taşınması daha akıllıca olacaktır. Bu hassasiyet, token boyutunu gereksiz yere büyütmeksizin microservice mimarisindeki veri akışını daha temiz ve verimli hale getirecektir. - Versiyonlama önemsenmelidir!
Token yapısı değiştiğinde (yeni claim eklendiğinde, mevcut bir claim’in yapısı yahut adı değiştiğinde) eski versiyona tabii client’lar aniden patlayabilir ve kullanıcılar giriş yapamaz hale gelebilir. Bu riski önlemenin ileri seviye çözümü, token’lara claim versiyonlaması eklemek ve her daim backward compatibility’yi (geriye dönük uyumluluk) gözetmektir. Böylece yeni token yapısına geçilse bile eski client’lar sorunsuz çalışmaya devam edecektir. Versiyonlama sayesinde token yapısını özgürce evriltebilir ve yeni özellikler ekleyebilirken bir yandan da mevcut kullanıcı deneyimini koruyabiliriz. Bu yaklaşım, uzun ömürlü ve sağlam bir authentication sistemi kurmanın en kritik parçalarından birisidir.
13 Kritik Soru / 13 Kritik Cevap
Soru 1 | Token Mapper olmasaydı ne yapardık?
Mapper, token içine veri koyarak stateless authentication sağlar. Dolayısıyla olmasaydı, her request’te erişmemiz gereken verilere DB / UserInfo endpoint’lerini çağırarak erişmemiz gerecekti! Böylece latency artacak, sistem yavaşlayacak ve microservice’lerde de bağımlılık riski söz konusu olabilecektir. Mapper’lar sayesinde lazım olan veriler her servisin direkt okuyacağı şekilde baştan token’a koyulmaktadır. Bu da bizlere performans ve olası maliyetler açısından büyük avantajlar sağlamaktadır.
Soru 2 | Token’a neler koyulmamalıdır?
Şifreler, TCKN gibi hassas kişisel veriler koyulmamalıdır. Çünkü, token decode edilerek hassas veriler başkaları tarafından rahatlıkla elde edilebilmektedir.
Ayrıca listeler ve JSON blob’lar gibi büyük veriler de koyulmamalıdır! Çünkü, token boyutu performansı etkilemektedir.
Soru 3 | Mapper’ı access token’a mı yoksa ID token’a mı eklemeliyiz?
Eğer API’de kullanılacaksa access token’a, yok eğer UI’da kullanılacaksa ID token’a eklenmelidir.
Soru 4 | Neden client scope diye bir şey var?
Client scope, mapper’ları tek tek her client manuel olarak eklemek yerine, reusable bir paket olarak yönetilmesini sağlayan akıllı bir mekanizmadır. Misal olarak; 10 adet microservice’in söz konusu olduğu bir senaryoda bir mapper’ı hepsinde kullanmak gerekiyorsa her servise ayrı ayrı mapper eklemek hem zaman hem de bakım açısından külfettir. Bunun yerine bir client scope oluşturup mapper’ı bu scope’un içine koyar, ardından ilgili tüm client’lar bu scope’a bağlanırsa, hem mapper tek bir yerden yönetilmiş hem de tüm client’lara otomatik olarak uygulanmış olacaktır. Bu sayede merkezi yapılandırma eşliğinde temiz ve düzenli bir yönetim sağlanmış olur.
Soru 5 | Mapper runtime’da mı çalışır yoksa login sırasında mı?
Sadece token oluşturulurken yani login sırasında çalışır! Ayrıca refresh token kullanıldığında da çalışacaktır.
Soru 6 | Token’daki veri güncel değilse ne olur?
Token immutable’dır. Haliyle eski token’lar da eski veriler mevcuttur. Çözüm olarak kısa token ömrü verilmeli, mümkün mertebe refresh token ve revoke mekanizmasından istifade edilmelidir.
Soru 7 | Mapper ile authorization yapılır mı?
Mapper sadece token’a veri taşır.
Soru 8 | Script Mapper ne zaman kullanılır?
- Veri transform edilecekse
- Birden fazla attribute birleşecekse
- Conditional logic gerekiyorsa
Bu durumlarda script mapper tercih edilebilir. Misal olarak; role + department → permission üretimi gibi durumlar için akla gelmelidir.
Ama unutulmamalıdır ki, performans maliyeti mevcuttur ve bakım süreci ister istemez zorlaşmaktadır.
Soru 9 | Mapper performansı etkiler mi?
Elbet etkileyecektir. Özellikle login sürecinde mapper’ların devreye girmesi hem süreci uzatacağı hem de token boyutunu büyüteceği için tüm bunlar network maliyetine yansıyacaktır.
Özellikle script mapper ve external data mapper durumları haddinden fazla maliyetli olacağı için dikkat edilmelidir.
Soru 10 | Mapper ile multi-tenant yapı kurulur mu? Ya da bir başka deyişle tenant bilgisi mapper ile yönetilebilir mi?
Mapper’lar kullanılarak multi-tenant bir yapı kurmak oldukça yaygın ve pratik bir yaklaşımdır. Kullanıcıya ait tenant bilgisi token içine bir claim olarak eklenerek her istekte bu bilginin taşınması sağlanır ve böylece backend tarafında gelen request’lerdeki tenant bilgisi ile token’daki tenant karşılaştırılarak yetki kontrolü ilgili tenant kapsamında gerçekleştirilip işlemler yürütülür.
Soru 11 | Mapper ile dynamic permission yapılır mı?
Hayır… Mapper, permission’ı token’a koyar ama runtime’da değiştiremez! Yani bu ihtiyaç için token mapper’lar yetersiz kalmaktadır. Dinamik yetkilendirme senaryolarını çözebilmek için policy engine veya DB lookup gibi çözümlere gidilmesi önerilmektedir.
Policy Engine, yetki kararlarını sabit token içinden okumak yerine, dışarıda çalışan bir karar motoruna soran bir yapılanmadır. Örneğin; Open Policy Agent (OPA), -bu kullanıcı şu kaynağa erişebilir mi?- sorusunu runtime’da kurallara göre değerlendirerek dinamik bir şekilde yönlendirmede bulunabilir. Böylece roller veya claim’ler statik değildir, bilakis anlık kurallar ve bağlama göre şekillenecektir.
DB lookup ise daha basit olsa da yine de dinamik bir davranış sergileyen yaklaşımdır. Burada uygulama, gelen request’teki kullanıcı bilgisine bakıp veritabanına gider ve güncel yetkileri, tenant bilgisini veya izinleri o anda çeker. ani token’daki bilgiye körü körüne güvenmek yerine -en güncel veri ne?- diyerek her istekte kontrol sağlar.
Soru 12 | Mapper ile UserInfo endpoint farkı nedir?
Mapper ile UserInfo aynı amaca hizmet eden iki farklı yaklaşımdır.
Mapper, Keycloak içinde tanımlanan bir özelliktir, yani config’tir. Login anında çalışır ve kullanıcı bilgilerini token’ın içine gömmemizi sağlar. Sonrasında ise uygulama bu bilgileri başka hiçbir yere gitmeye gerek kalmaksızın direkt token içerisinden okuyabilir. Yani stateless’dir.
UserInfo ise endpoint’tir. Token’ı alıp Keycloak’a tekrar istek atarak kullanıcıya dair bilgiler edinilmesini sağlar. Keycloak, bu istek neticesinde o anki bilgiyi döner. Dolayısıyla her seferinde bir dış çağrı gerektirir. Bundan kaynaklı stateful’dur.
Stateless, sistemin çalışmak için ekstra bir yere (DB, servis vs.) gidip bilgi talep etmesine gerek olmaması, yani tüm gerekli bilginin token’da bulunmasıdır.
Stateful ise, sistmein karar verebilmesi için her istekte dış bir kaynağa gidip güncel durumu kontrol etmesi demektir.
Mapper → Bilgiyi baştan cebime koyarım…
UserInfo → Bilgi gerektikçe gidip sorarım…
Soru 13 | Mapper ile security açığı oluşur mu?
Evet! token’ın public olmasından dolayı hassas verilerin sızdırılması olasıdır. Dikkat edilmelidir!
Token Mapper’ların Kullanımı
Şimdi sıra token mapper’ları deneyimlemeye geldi.
İlk olarak Keycloak’da bir kullanıcının edindiği token’ın en sade haliyle nasıl bir içeriğe sahip olduğunu inceleyelim…
 Evet… Görüldüğü üzere bir kullanıcıda varsayılan olarak aşağı yukarı yandaki görseldeki gibi içeriğe sahip bir token yapısı gelmektedir.
Evet… Görüldüğü üzere bir kullanıcıda varsayılan olarak aşağı yukarı yandaki görseldeki gibi içeriğe sahip bir token yapısı gelmektedir.
Tabi ki de kullanıcıya rol yahut yetki verdikçe buradaki payload şekillenecektir. Çünkü bu claim’ler zaten bu kaynaklardan beslenmektedir. Ancak ana claim’lerin yanına ekstradan bir kullanıcı bilgisi eklemek isterseniz burada attribute oluşturup mapper’lar ile eklemeniz en doğru yaklaşım olacaktır. Bu yaklaşım, yukarıdaki satırlarda Mapper Türleri Nelerdir? başlığı altında değerlendirdiğimiz User Attribute Mapper türüne karşılık gelmektedir.
Diyelim ki, kullanıcıların department bilgisini token’a claim olarak eklemek istiyoruz. Tabi bunun için öncelikle ilgili isimde bir attribute eklenmesi gerekecektir.
Bu da Realm settings üzerinden User profile sekmesine gelerek gerçekleştirilebilir. Şimdi normal şartlarda, bu attribute’u ekledikten sonra aşağıdaki gibi kullanıcı detaylarından doldurulup kaydedildiğinde token’a gelmesini bekleyebilirsiniz.
Şimdi normal şartlarda, bu attribute’u ekledikten sonra aşağıdaki gibi kullanıcı detaylarından doldurulup kaydedildiğinde token’a gelmesini bekleyebilirsiniz. Ancak nafile… Bu attribute tarafımızca oluşturulduğu ve sistem tarafından bilinmediği için bizim tarafımızdan token’a eklenmesi gerekecektir. Bunun için mapper oluşturulması gerekmektedir.
Ancak nafile… Bu attribute tarafımızca oluşturulduğu ve sistem tarafından bilinmediği için bizim tarafımızdan token’a eklenmesi gerekecektir. Bunun için mapper oluşturulması gerekmektedir.
Token Mapper Oluşturma
 Token mapper oluşturmanın en temiz ve doğru yolu scope olarak oluşturmaktır. Bunun için
Token mapper oluşturmanın en temiz ve doğru yolu scope olarak oluşturmaktır. Bunun için Client Scopes menüsüne gelerek bir scope oluşturulmalıdır.
Şimdi bu scope’a oluşturacağımız mapper ile hem istediğimiz attribute’u token’a ekleyebileceğiz hem de istediğimiz client’ta bu scope’u çağırarak, o client’tan olacak login süreçlerinde mapper’dan istifade edebiliyor olacağız. Böylece bir mapper’ı scope üzerinden tek seferde tanımlayıp, farklı client’larda kullanabilecek ve tekrar tekrar tanımlama zahmetinden kurtulmuş olacağız.
Devam etmeden önce akıllara gelebilecek olan ideal olan her mapper için ayrı bir scope oluşturmak mı? sorusunu cevaplandıralım istiyorum… El-cevap: Hayır. Her mapper için ayrı bir scope oluşturmak doğru bir kabul olmayacaktır. Çünkü, scope dediğimiz şey esasında mantıksal bir paket gibi düşünülebilir. Yani claim’leri tek tek ayrı scope’lara dağıtmak yerine, birbiriyle ilişkili olanları aynı scope içine toplamak en doğrusu olacaktır. Misal olarak; profile-data diye bir scope açıp içine name, surname, department vs. gibi mapper’ları koymak ya da authorization-data diye bir scope içerisine de roles, groups vs. gibi claim’leri depolamak en mantıklısıdır. Olaya mantıksal olarak bakarsak eğer; mapper’lar, tekil kuralken, scope’lar ise bu kuralların mantıklı gruplandığı paketler olarak düşünülebilir. O yüzden her mapper’a ayrı bir scope değil, anlamlı gruplara göre scope oluşturmak en sağlıklı kabul olacaktır.
Velhasıl…
İlgili scope’a tıklayıp Mappers sekmesine geldiğimizde bizleri aşağıdaki gibi iki seçenek karşılayacaktır:
|
Add predefined mapper
Hazır mapper’ları tek tıkla eklemesini sağlar, ekstra config gerektirmez.
email, preferred_username, roles |
Configure a new mapper
Custom mapper oluşturulmasını sağlar, claim tamamen tarafımızca tanımlanır.
department → "IT" |
Bizler senaryomuza uygun olarak Configure a new mapper seçeneğinden devam edeceğiz.
User Attribute Mapper Oluşturma
İlgili seçeneğe tıkladığımızda açılan pencereden aşağıdaki gibi User Attribute türü seçilmeli,
 ve ardından yandaki gibi ilgili mapper yapılandırılmalıdır.
ve ardından yandaki gibi ilgili mapper yapılandırılmalıdır.
Buradaki yapılandırmalara değinmemiz gerekirse eğer;
- Mapper type: Mapper’ın türünü ifade etmektedir.
- Name: Teknik olarak hiçbir şeye etki etmiyor olsa da mapper’ın Keycloak içindeki ismine karşılık gelmektedir.
- User Attribute: User’ın hangi attribute’una karşılık bu mapper’ın oluşturulduğu belirlenmektedir.
- Token Claim Name: Token’da hangi claim’e karşılık bu değerin ekleneceği belirlenmektedir.
- Claim JSON Type: Verinin tipi belirlenmektedir.
- Add to ID token: Claim’in ID token’a eklenip eklenmeyeceğini yapılandırmaktadır.
- Add to access token: Benzer mantıkla claim’in access token’a eklenip eklenmeyeceğini yapılandırmaktadır.
- Add to lightweight access token: Standart kullanımın dışında kalan bir optimizasyondur. Keycloak, token’ı küçültmek ve daha hızlı taşıyabilmek için kimi zaman hafif (lightweight) access token üretimi gerçekleştirebilmektedir. İşte bu ayar, bu durumlarda ilgili claim’in eklenip eklenmeyeceğini yapılandırmaktadır.
- Add to userinfo: UserInfo endpoint’i çağrıldığında bu verinin dönüp dönmeyeceği belirlenmektedir.
- Add to token introspection: Token introspection endpoint’inde bu claim’in görünüp görünmeyeceği yapılandırılmaktadır.
- Multivalued: İlgili claim’in değerinin çoklu olup olmayacağını yapılandırmaktadır. Eğer çoklu olursa değeri bir array içerisinde getirecektir.
- Off
"department": "IT"
- On
"department": ["IT", "HR"]
- Off
- Aggregate attribute values: Eğer kullanıcıda aynı attribute’tan birden fazla mevcutsa hepsini birleştirip birleştirmeyeceğini yapılandırmaktadır. Kapalı kaldığı taktirde ilk değeri alacaktır.
Evet, bu yapılandırma ayarlarında bir mapper’ı oluşturduktan sonra ilgili client üzerinden elde edilen token’ın payload’una göz atarsak aşağıdaki gibi department değerinin geldiğini gözlemlemiş olacağız…
Hardcoded Mapper Oluşturma
Peki… Örneğimizi genişletmek adına bir de sabit değerlerin token’a nasıl eklendiğini inceleyelim. Tabi bunun için de Hardcoded Mapper oluşturmamız gerekecektir.
Bu sabit değer için uygun bir scope oluşturabiliriz. Mesela; info adında bir scope’umuz olsun.
Bu scope’a Configure a new mapper seçeneği üzerinden Hardcoded claim‘i seçerek sabit bir değer ekleyebiliriz.  Evet, görselde eksik kalan yapılandırmaları önceki satırdakilerle aynı olacağı için es geçmiş bulunuyorum. Bu şekilde bir mapper’ı oluşturup,
Evet, görselde eksik kalan yapılandırmaları önceki satırdakilerle aynı olacağı için es geçmiş bulunuyorum. Bu şekilde bir mapper’ı oluşturup, info scope’unu da ilgili client’a ekleyerek bir token talep edersek, bu token içerisinde aşağıdaki görselde olduğu gibi sabit değerin de geldiğini görmüş olacağız.
İşte bu kadar…
Geri kalan mapper türlerini tecrübe etmeyi sizlere bırakıyorum 😉
Nihai olarak;
Token’a koyulan her veri, esasında sisteme atılan bir imzadır… Ya performansı hızlandırır ya da fark etmeden sistemi yavaşlatır… Ya güveliği güçlendirir ya da zafiyet oluşturabilir… Token Mapper’lar bu yüzden basit bir özellik değildir, bilakis doğru kullanıldığında ihtiyaç gideren ancak yanlış kullanıldığında ayağa dolaşıp tökezleten stratejik bir yapılanmadır. Bu yüzden mesele hiçbir zaman -token’a ne koyabilirim?- sorusu değildir! -gerçekten neyi koymalıyım?- sorusudur… Bu soruya verilen cevap, kurulan sistemin kalitesiyle doğru orantılıdır.
İlgilenenlerin faydalanması dileğiyle…
Sonraki yazılarımda görüşmek üzere…
İyi çalışmalar…