Kubernetes | KEDA İle Queue Uzunluğuna Göre Consumer Deployment’ı Otomatik Ölçeklendirme
 Merhaba,
Merhaba,
Günümüzün cloud-native mimarilerinde ölçeklenebilirlik yalnızca sistem performansının değil, aynı zamanda operasyonel verimliliğin de belirleyici faktörlerinden birisidir. Özellikle microservice yapılarında, her bileşenin farklı yük profillerine sahip olması; yatay ölçeklemenin dinamik, esnek ve akıllı mekanizmalarla yürütülmesini zorunlu kılmaktadır.
Bu bağlamda, mesaj tabanlı sistemler (message-driven architectures) ayrı bir dikkat gerektirmektedir. Bir RabbitMQ kuyruğuna saniyeler içinde binlerce mesajın akması, ancak belirli bir vade yoğunluk olduktan ve duraksama yaşandıktan sonrasında trafiğin sıfırlanması sık rastlanan bir durumdur. Haliyle kuyruklardaki yük genellikle sabit değil, dalgalıdır. Bu kadar değişken bir yük altında, yalnızca CPU ya da bellek kullanımına dayalı klasik Kubernetes ölçekleme modelleri (örneğin; HPA — Horizontal Pod Autoscaler) çoğu zaman yetersiz kalmaktadır. Çünkü sistemin gerçekte ne kadar yük altında olduğunu anlamanın yolu CPU’da değil, kuyruktaki mesaj sayısında (queue length) gizlidir.
Tam da bu noktada KEDA (Kubernetes Event-Driven Autoscaler) devreye girmektedir. KEDA, Kubernetes’e olay güdümlü bir ölçekleme yeteneği kazandırarak, uygulamaların doğrudan iş yükü metriklerine (örneğin; bir RabbitMQ kuyruğundaki mesaj sayısına) tepki vermesini sağlamaktadır. Bu sayede sistemler yalnızca kaynak kullanımına değil, işin kendisine -yani olayın hacmine- duyarlı hale gelmektedir.
Bu içeriğimizde, Kubernetes üzerinde KEDA kullanarak bir RabbitMQ message broker’ı ile haberleşen .NET consumer servisinin kuyruk uzunluğuna göre otomatik ölçeklenmesini ele alacak ve bir yandan teorik temelleri açıklarken bir yandan da pratikte uygulanabilir bir mimari örneği sunmaya çalışacağız.
O halde buyurun başlayalım…
KEDA’nın Amacı ve Çıkış Noktası
KEDA, Kubernetes’e mesaj kuyruğundaki gerçek yükü görme yeteneği kazandıran önemli bir bileşendir.
Kubernetes’in yerleşik otomatik ölçekleyicisi olan HPA (Horizontal Pod Autoscaler) yalnızca CPU veya bellek gibi metrikleri izlemekte ancak microservice tabanlı sistemlerde yük her zaman bu kaynaklara doğrudan yansımayacağı için kimi kritik durumlarda pek ihtiyacımızı karşılayamamakta ve önceki satırlarda belirttiğimiz gibi ister istemez yetersiz kalmaktadır. Bizler bunu message broker kullandığımız senaryolarda yer yer tecrübe ettiğimizi söylebiliriz. Misal olarak; RabbitMQ kullanılan kimi çalışmalarda queue’da binlerce mesajın biriktiğini amma velakin consumer’ların CPU’sunun boşta olduğunu muhtemelen görmüşsünüzdür. İşte böyle durumlarda HPA, kendisinden beklenen ölçeklendirmeyi gerçekleştirememekte ve günün sonunda maliyet tüm faturasıyla sistemin geneline ve hatta daha da kötüsü son kullanıcıya kadar yansıtılabilmektedir.
Benzer mantıkla, e-ticaret sistemlerinde yeni ürün yüklemeleri yapıldığı taktirde aniden binlerce ‘update’ mesajı gönderilmek istendiği durumlarda sistem birkaç dakika içinde tüm güncellemeleri işleyerek, kısa süre sonra sessizliğe bürünebilmektedir. Yani sanki hiç çalışma olmamış gibi CPU’da bir dalgalanma söz konusu olmayacak ve esasında kuyruk bir süreliğine şişmiş olacağından, o kısır sürede HPA ölçeklendirme görevini yerine getiremeyecektir.
Bir başka örneği de zamanında üzerinde çalıştığım video işleme uygulamasından vermek istiyorum. Kullanıcılar tarafından yapılan video yüklemeleri neticesinde, sistem farklı bir serviste bu videoları istekler doğrultusunda işleyerek filigran eşliğinde indirilmek üzere panele düşürmekteydi. Nedendir bilinmez… Kimi zaman dakikalar içerisinde onlarca video yükleniyor, ardından saatlerce hiç yükleme olmuyordu. Evet, böyle bir durumda da CPU hep sabit metrik sunmaktaydı. İşte bu senaryoda da HPA ile ölçeklendirme söz konusu olmayacak, sistem o kısa aralıkta tüm yükü tek bir instance üzerine yükleyerek belki o anı darboğaz bir vaziyette geçirmiş olacaktır.
Bunlar gibi türlü senaryolardan anlayacağımız üzere iş yükü durumu genellikle doğrudan CPU’ya yansımıyor olsa da kuyruk uzunluğu gibi başka bir gösterge noktasında kendini belli etmektedir. Bizler de, uygulamaların davranışlarına dair daha farklı ve spesifik metriklere göre bir ölçeklendirme ihtiyacını elzem görmekteyiz. Bunun için de KEDA imdadımıza yetişmekte, CPU dışı uygulama özel metriklerine göre sistemi ölçeklendirebilmemizi sağlayan oldukça kritik bir bileşen olarak karşımıza çıkmaktadır.
KEDA, esasında Kubernetes ekosisteminde ‘event-driven autoscaling’ (olay güdümlü otomatik ölçekleme) sağlayan open source bir bileşendir. Ölçeklendirmeyi, CPU ya da bellek kullanımına göre değil, uygulamanın iş yüküyle ilgili olan kuyruğa gelen mesaj sayısı gibi olaylara göre gerçekleştirmekte ve Pod sayısını dinamik biçimde ayarlayarak otomatik hale getirmektedir.
KEDA’nın Temel Bileşenleri Nelerdir?
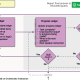
KEDA yapısal olarak Operator (Controller), Metrics Adapter ve Scaler olmak üzere üç ana bileşenden oluşmaktadır;
| Operator (Controller) | |
|---|---|
Kubernetes API’siyle entegre çalışan bileşendir. ScaledObject ve ScaledJob türünden nesneleri izlemektedir. Bu nesneler, KEDA’nın temel bileşenleri olarak kabul edilmektedir.
Bu bileşenler, KEDA’nın Kubernetes’e özel Custom Resource Definitions (CRD’leri) olup, olay kaynaklarını (örneğin; kuyruk uzunluğu veya mesaj sayısı gibi) Kubernetes iş yükleriyle eşleştirerek ölçeklendirme kurallarını tanımlamaktadırlar. Ve bir yandan bu bileşenler, Horizontal Pod Autoscaler (HPA) ile entegre çalışmakta ve KEDA’nın olay tabanlı ölçeklendirme çekirdeğini oluşturmaktadırlar. Aşağıdaki bu iki bileşeni detaylı bir şekilde açıklayalım; |
|
|
|
| Özetlersek eğer;ScaledObject, sürekli çalışan Deployment’ı ölçeklerken, ScaledJob ise her olay için kısa süreli çalışacak ve tamamlanınca bitecek olan yeni bir Job başlatmaktadır. | |
| Metrics Adapter | |
|---|---|
| KEDA’nın en kritik bileşenlerinden biridir. Bunu anlamadan KEDA’nın nasıl çalıştığı tam kavranamayacağı kanaatindeyim.
KEDA Metrics Adapter, Kubernetes HPA ile KEDA’nın olay tabanlı metrikleri arasında köprü görevi gören bir API sunucusudur. Nasıl ki; ScaledObject ve ScaledJob bileşenleri KEDA’nın ölçekleme kurallarını tanımlamakta; Scaler, kuyruk uzunlu vs. gibi gerçek metrikleri çekmekte… Metrics Adapter ise bu metrikleri HPA’nın anlayacağı formata çevirmektedir. Nasıl çalışır?
Evet, böylece sadece CPU, Memory veya Custom Metris API’lerini destekleyen HPA’ya, Metrics Adapter sayesinde herhangi bir olay kaynağını verebilmekteyiz. HPA, external metrikleri doğrudan okuyamadığı için dış dünyadaki metrikleri ancak Metrics Adapter sayesinde Kubernetes içerisinde aktarabilmekteyiz.
.
.
.
triggers:
- type: rabbitmq
metadata:
queueName: my-queue
queueLength: "10"
Yukarıdaki gibi bir yapılandırma neticesinde Metris Adapter,
|

| Scaler | |
|---|---|
| Bu bileşen de KEDA’nın kalbidir diyebiliriz. Diğer bileşenlerdeki rolünden de anlaşılacağı üzere olay kaynaklarından (RabbitMQ, Kafka, Azure Queue vs.) metrikleri gerçek zamanlı çeken bileşendir diyebiliriz.Scaler, özellikle Metrics Adapters ile entegre çalışmakta ve 50+ farklı scaler desteklemektedir (ve Cloud Native Computing Foundation (CNCF) projesi olarak sürekli güncellenmektedir)
Diğer bileşenlerle bağlantısı nasıldır?
|
KEDA’nın Desteklediği Kaynak Türleri Nelerdir?
KEDA, pek çok sistemi desteklemektedir ve bunlar trigger olarak adlandırılmaktadır. Zaten yukarıdaki satırlarda verilen örneklere göz atarsanız bu kaynakların triggers alanı altında tanımlandığını görürsünüz. Burada öncelikle KEDA’da karıştırılma ihtimali yüksek olan trigger ile scaler kavramlarının farkını net ortaya koyarak, olası hataya düşürebilecek bu durumu netleştirerek devam edelim istiyorum.
| Trigger | Scaler |
|---|---|
Trigger, KEDA’ya şu minvalde bir davranış sergiletir: Şu kaynağa bak, belirli bir eşik aşılırsa ölçeklemeyi başlat. Bu mantıkla yola çıkıldığında; message broker kuyruğundaki mesaj sayısı, Kafka’daki lag değeri, Prometheus metriklerinden bir sayaç değeri yahut Azure Service Bus’taki aktif mesaj sayısı KEDA için bir trigger’a karşılık gelmektedir. Yani her trigger bir veri kaynağını temsil etmekte ve belirli metrikleri izlemektedir.
|
Scaler ise trigger’ın teknik karşılığıdır. Yani trigger’ın arka plandaki mantığını işleten bileşendir. |
Her trigger türü için KEDA’nın içinde bir scaler modülü mevcuttur. Bu scaler, belirli bir sisteme bağlanır, metrikleri toplar ve KEDA’ya ‘ölçeklendirme zamanı geldi’ sinyalini verir.
Misal olarak; RabbitMQ Scaler’i RabbitMQ API’sine bağlanır ve queueLength değerini alır. Benzer mantıkla Kafka Scaler’i de consumer lag bilgisini çeker.
Yani her trigger tipi, aslında bir scaler implementasyonu tarafından gerçekleştirilir.
Scaler, bu trigger bilgiyi nasıl toplayacak ve ölçeklendirmeyi nasıl başlatacak sorusunun cevabıdır.
Ne izleneceğini tanımlar.İzlemeyi ve metrik toplayı teknik olarak yapar.
Evet, bu ayrımı gerçekleştirdikten sonra esas başlığın içeriğine odaklanabiliriz 🙂
KEDA’da aşağıdaki gibi birçok trigger mevcuttur;
- Messaging sistemler
RabbitMQ, Kafka, Azure Service Bus, NATS, AWS SQS - Veri kaynakları
PostgreSQL, MySQL, MongoDB - Cloud servisleri
AWS CloudWatch, Azure Monitor, Google Pub/Sub - Custom metrics
Prometheus metrikleri, HTTP endpoint’ler
Bu belirtilenlerin dışında en güncel haliyle 60 ve üzeri trigger’ın mevcut olduğunu söyleyebiliriz.
Evet… Artık KEDA’ya dair teoride yeterince farkındalık oluşturduğumuza göre konunun pratik yönünü incelemeye geçebiliriz.
KEDA İle Dinamik Ölçeklendirme Çalışması
Yazımızın bundan sonraki bölümünde, basit bir senaryoya karşın geliştirdiğimiz, RabbitMQ ile aralarında haberleşmeyi sağlayan iki servisten consumer tarafını KEDA ile dinamik olarak ölçeklendirecek davranışı pratiksel olarak ele alıyor olacağız. Tabi bunu yaparken, olayın ana noktasını daha iyi kavrayabilmeniz için önce Kubernetes ile konteyner’leri ayağa kaldıracak, ardından KEDA entegrasyonu ve yapılandırması eşliğinde dinamik ölçeklendirmenin farkını ortaya koyacağız. Hadi buyurun başlayalım 🙂
Servislerin Geliştirilmesi
Şimdi ilk olarak servisimizi geliştirerek başlayalım. Bunun için aşağıdaki adımların sırasıyla seyredilmesi yeterli olacaktır…
- Adım 1 (KedaQueueAutoScaler.Publisher Servisinin Oluşturulması)
Dinamik ölçeklendirme sürecinde kuyruk için yoğun mesaj üretimini test amaçlı üstlenecek olan servistir.İlk olarak bu servise MassTransit.RabbitMQ kütüphanesini yükleyelim ve ardından Program.cs dosyasında aşağıdaki çalışmayı gerçekleştirelim.
Örnek kodu görmek için tıklayınız
using KedaQueueAutoScaler.Shared.Messages; using MassTransit; using MassTransit.Testing.Implementations; var builder = WebApplication.CreateBuilder(args); builder.Logging.ClearProviders(); builder.Logging.AddSimpleConsole(options => { options.SingleLine = true; options.TimestampFormat = "HH:mm:ss "; }); builder.Services.AddMassTransit(configurator => { configurator.UsingRabbitMq((context, _configurator) => { _configurator.Host("10.1.1.125", 5672, "/", h => { h.Username("admin"); h.Password("admin"); }); _configurator.ConfigureEndpoints(context); }); }); var app = builder.Build(); app.MapGet("/", async (ILogger<Program> logger, ISendEndpointProvider sendEndpointProvider) => { var endpoint = await sendEndpointProvider.GetSendEndpoint(new Uri("queue:keda-queue-autoscaler-queue")); logger.LogInformation("3000 mesaj paralel gönderiliyor..."); var startTime = DateTime.UtcNow; var batchSize = 100; var totalMessages = 3000; for (int batchStart = 0; batchStart < totalMessages; batchStart += batchSize) { var tasks = new List<Task>(); for (int i = batchStart; i < batchStart + batchSize && i < totalMessages; i++) { int messageNumber = i; tasks.Add(endpoint.Send<ExampleMessage>(new ExampleMessage(messageNumber, $"Message {messageNumber}"))); } await Task.WhenAll(tasks); logger.LogInformation($"{batchStart + batchSize} mesaj gönderildi..."); } var duration = DateTime.UtcNow - startTime; logger.LogInformation($"3000 mesaj {duration.TotalSeconds:F2} saniyede gönderildi"); return Results.Ok(new { Success = true, MessageCount = 3000, DurationSeconds = duration.TotalSeconds }); }); app.Run(); - Adım 2 (KedaQueueAutoScaler.Consumer Servisinin Oluşturulması)
RabbitMQ kuyruğunu dinleyip, tüketecek ve günün sonunda kuyruktaki mesaj sayısında belirli bir oranın üzerinde yoğunluk söz konusuysa dinamik olarak ölçeklendirilecek olan servistir.Bu servise de yine MassTransit.RabbitMQ kütüphanesini yükleyelim ve ardından mesajları tüketecek olan aşağıdaki consumer sınıfını inşa edelim.
Örnek kodu görmek için tıklayınız
using KedaQueueAutoScaler.Shared.Messages; using MassTransit; namespace KedaQueueAutoScaler.Consumer.Consumers { public class ExampleMessageConsumer(ILogger<ExampleMessageConsumer> logger) : IConsumer<ExampleMessage> { public async Task Consume(ConsumeContext<ExampleMessage> context) { await Task.Delay(1000); logger.LogInformation($"Received message no : {context.Message.MessageNo} | message text : {context.Message.Text}"); } } }Ardından Program.cs dosyasında da aşağıdaki gibi yapılandırmada bulunalım.
Örnek kodu görmek için tıklayınız
using KedaQueueAutoScaler.Consumer.Consumers; using MassTransit; var builder = Host.CreateApplicationBuilder(args); builder.Logging.ClearProviders(); builder.Logging.AddSimpleConsole(options => { options.SingleLine = true; options.TimestampFormat = "HH:mm:ss "; }); builder.Services.AddMassTransit(configurator => { configurator.AddConsumer<ExampleMessageConsumer>(); configurator.UsingRabbitMq((context, _configurator) => { _configurator.Host("10.1.1.125", 5672, "/", h => { h.Username("admin"); h.Password("admin"); }); _configurator.ReceiveEndpoint("keda-queue-autoscaler-queue", endpointConfigurator => { endpointConfigurator.Consumer<ExampleMessageConsumer>(context); }); _configurator.ConfigureEndpoints(context); }); }); var host = builder.Build(); host.Run(); - Adım 3 (KedaQueueAutoScaler.Shared Class Library’sinin Oluşturulması)
.NET ile message broker çalışmalarında servisler arası haberleşmeyi sağlayan türleri barındıran klasikleşmiş class library’dir.İçerisinde iletişim sürecinde kullandığımız
ExampleMessagesınıfını aşağıdaki gibi tanımlamış olmamız yeterli olacaktır.Örnek kodu görmek için tıklayınız
namespace KedaQueueAutoScaler.Shared.Messages { public record ExampleMessage(int MessageNo, string Text); }
Uyarı!
Yukarıdaki kodlarda bağlantı sağlanan RabbitMQ IP’si (10.1.1.125) aşağıdaki RabbitMQ Kurulumu başlığındaki yönergeler uygulandıktan sonrakubectl get pod rabbitmq-0 -n default -o jsonpath='{.status.podIP}'talimatı eşliğinde elde edilerek koda yerleştirilmiştir.
RabbitMQ Kurulumu
Şimdi de message broker olarak RabbitMQ’nun kurulumunu ele alalım. Tabi bunun için Kubernetes’in paket yöneticisi olan Helm‘den istifade edeceğiz. Helm, bir uygulamanın tüm Kubernetes manifest dosyalarını (Deployment, Service, ConfigMap vs.) Chart adı verilen tek bir yapı içinde toplamaktadır. Bu özelliği sayesinde, herhangi bir pakete dair kurulumu tek seferde helm install talimatı eşliğinde rahatlıkla gerçekleştirebilmemizi sağlamaktadır.
Helm ile bir paket yükleyebilmek için öncelikle Helm’in kurulması gerekmektedir. Bunun için PowerShell üzerinden winget install Helm.Helm talimatını verebilirsiniz.
Kurulumu gerçekleştirdikten sonra Bitnami Helm reposunun eklenmesi gerekmektedir. Hoca bu repo ne la? dediğinizi duyar gibiyim… Bu, VMware’in bir alt markası olan ve Kubernetes için resmi ve güvenilir Helm chart’ları sağlayan bir havuzdur. RabbitMQ, Redis, PostgreSQL, MongoDB vs. gibi popüler servislerin hazır ve test edilmiş versiyonlarının tek komutla kurulabilmesini sağlamaktadır.
Velhasıl Bitnami Helm reposunu sisteme ekleyebilmek için aşağıdaki talimatı çalıştıralım.
helm repo add bitnami https://charts.bitnami.com/bitnami
Ardından sistemde kayıtlı olan tüm Helm repolarını güncelleyelim.
helm repo update
Artık RabbitMQ’yu yükleyebiliriz.
helm install rabbitmq bitnami/rabbitmq --set persistence.enabled=false --set auth.username=admin --set auth.password=admin --set hostname=rabbitmq
Yüklediğimiz bu RabbitMQ instance’ının dışarıdan erişilebilir olması için gerekli portları local ortamdan erişime açmamız gerekmektedir.
kubectl port-forward svc/rabbitmq -n default 5672:5672 15672:15672
İşte bu kadar… Artık RabbitMQ’yu rahatlıkla kullanabiliriz.
Dikkat!
Talihsizliktir ki son günlerde VMWare, Bitnami politikasını değiştirdi ve
bitnami/rabbitmqimage’ını ücretli hale getirdi! Bu karardan dolayı https://hub.docker.com/r/bitnami/rabbitmq adresinden de görebileceğiniz üzere ilgili image’ın herhangi bir tag’ine erişilememekte, dolayısıyla yukarıdaki talimatlar doğrultusunda RabbitMQ konteyner’ı ayağa kaldırılırken türlü türlü ‘image pull’ vs. gibi hatalarla karşılaşılmaktadır.Ancak VMWARE bu kararı eski RabbitMQ image’ları için uygulamamış ve bitnamilegacy altında erişime açık halde bırakmıştır. Bunun için tek yapılması gereken alternatif bir image’ı pull edebilmek için helm chart’ı aşağıdaki gibi ezmemiz (overwrite) ve ardından
helm installtalimatını belirtildiği gibi uygulamamız yeterli olacaktır.
values-rabbitmq.yaml;global: security: allowInsecureImages: true image: repository: bitnamilegacy/rabbitmq volumePermissions: enabled: true image: repository: bitnamilegacy/os-shell metrics: enabled: falsehelm install rabbitmq bitnami/rabbitmq --set persistence.enabled=false -f values-rabbitmq.yaml --set auth.username=admin --set auth.password=admin --set hostname=rabbitmq
Tüm bu işlemlerden sonra sağ salim RabbitMQ Pod’unu ayağa kaldırabildiyseniz eğer port-forward işlemi aşağıdaki gibi başarılı olacaktır. Ve bir yandan http://localhost:15672 adresi üzerinden RabbitMQ Management Dashboard’una erişim sağlanabilecektir.
Ve bir yandan http://localhost:15672 adresi üzerinden RabbitMQ Management Dashboard’una erişim sağlanabilecektir.
Kubernetes İle Konteynerleştirme
Şimdi de oluşturduğumuz servisleri Kubernetes ile konteynerleştirerek ayağa kaldıralım. Bunun için öncelikle her iki servisin image’ına ihtiyacımız olacaktır. Ee haliyle bunun için de bu servislerin ayrı ayrı Dockerfile dosyalarını oluşturmalı ve aşağıdaki gibi içeriklerini tasarlamalıyız.
KedaQueueAutoScaler.Publisher servisinin Dockerfile dosyası;
# Derleme aşaması: Uygulamanın derlenmesi için resmi .NET SDK 9.0 görüntüsünü temel alır
FROM mcr.microsoft.com/dotnet/sdk:9.0 AS build
# Konteyner içindeki çalışma dizinini /src olarak ayarlar
WORKDIR /src
# Tüm çözümü (tüm projeler ve dosyalar dahil) konteynere kopyalar
COPY . .
# Çözüm için NuGet paketlerini geri yükler
RUN dotnet restore
# Publisher projesini derler ve yayınlar
# -c Release: Release yapılandırmasında derler
# -o /app: /app dizinine çıktı verir
# --no-restore: Paketleri tekrar yüklemez (yukarıda zaten yapıldı)
RUN dotnet publish KedaQueueAutoScaler.Publisher/KedaQueueAutoScaler.Publisher.csproj \
-c Release -o /app --no-restore
# Çalışma zamanı aşaması: Daha küçük boyutlu ASP.NET Runtime görüntüsünü kullanır (bu bir web uygulaması olduğu için)
FROM mcr.microsoft.com/dotnet/aspnet:9.0 AS runtime
# Çalışma zamanı konteynerinde çalışma dizinini /app olarak ayarlar
WORKDIR /app
# Derleme aşamasında yayınlanan uygulamayı çalışma zamanı aşamasına kopyalar
COPY --from=build /app .
# ASP.NET Core URL'lerini 8080 portunu dinleyecek şekilde yapılandırır
ENV ASPNETCORE_URLS=http://+:8080
# Konteynerin 8080 portunu dinlediğini belirtir
EXPOSE 8080
# Uygulamayı çalıştıracak komutu tanımlar
ENTRYPOINT ["dotnet", "KedaQueueAutoScaler.Publisher.dll"]
KedaQueueAutoScaler.Consumer servisinin Dockerfile dosyası;
# Derleme aşaması: Uygulamanın derlenmesi için resmi .NET SDK 9.0 görüntüsünü temel alır
FROM mcr.microsoft.com/dotnet/sdk:9.0 AS build
# Konteyner içindeki çalışma dizinini /src olarak ayarlar
WORKDIR /src
# Tüm çözümü (tüm projeler ve dosyalar dahil) konteynere kopyalar
COPY . .
# Çözüm için NuGet paketlerini geri yükler
RUN dotnet restore
# Consumer projesini derler ve yayınlar
# -c Release: Release yapılandırmasında derler
# -o /app: /app dizinine çıktı verir
# --no-restore: Paketleri tekrar yüklemez (yukarıda zaten yapıldı)
RUN dotnet publish KedaQueueAutoScaler.Consumer/KedaQueueAutoScaler.Consumer.csproj \
-c Release -o /app --no-restore
# Çalışma zamanı aşaması: .NET Runtime görüntüsünü kullanır (bu bir worker service olduğu için ASP.NET Core değil)
FROM mcr.microsoft.com/dotnet/runtime:9.0
# Çalışma zamanı konteynerinde çalışma dizinini /app olarak ayarlar
WORKDIR /app
# Derleme aşamasında yayınlanan uygulamayı çalışma zamanı aşamasına kopyalar
COPY --from=build /app .
# Uygulamayı çalıştıracak komutu tanımlar
ENTRYPOINT ["dotnet", "KedaQueueAutoScaler.Consumer.dll"]
Evet, dikkat ederseniz servislerin türlerine göre Dockerfile dosyaları uygun talimatlarla yapılandırılmıştır.
Şimdi de bu Dockerfile dosyalarından image’leri oluşturalım. Tabi bunun için
docker build -t <image-name> -f KedaQueueAutoScaler.Publisher/Dockerfile . ve
docker build -t <image-name> -f KedaQueueAutoScaler.Consumer/Dockerfile . talimatlarını kullanarak image’leri oluşturabilirsiniz. Ancak bizler bu şekilde tek tek uğraşmak yerine süreci Docker Compose ile yürütüyor olacağız.
Solution’ın ana dizinine docker-compose.yaml adında bir dosya oluşturalım ve içeriğini aşağıdaki gibi dolduralım.
services:
publisher:
image: kedaqueueautoscaler.publisher
build:
dockerfile: KedaQueueAutoScaler.Publisher/Dockerfile
consumer:
image: kedaqueueautoscaler.consumer
build:
dockerfile: KedaQueueAutoScaler.Consumer/Dockerfile
Evet, artık bu Docker Compose dosyası üzerinden, tek seferde docker compose build talimatı eşliğinde tüm Dockerfile‘lara uygun image’leri oluşturabiliriz.  Image’ler oluşturulduğuna göre artık Kubernetes için gerekli yapılandırmaları kurgulamaya geçebiliriz.
Image’ler oluşturulduğuna göre artık Kubernetes için gerekli yapılandırmaları kurgulamaya geçebiliriz.
Şimdi bizlerin burada üç adet Kubernetes nesnesine ihtiyacı mevcuttur. Bunlardan ikisi hem publisher hem de consumer servisleri için birer Deployment nesnesi, diğeri ise publisher’ı dışardan erişilebilir hale getirecek olan Service nesnesidir. Hadi bunları oluşturarak devam edelim.
KedaQueueAutoScaler.Publisher.deployment.yaml;
apiVersion: apps/v1
kind: Deployment
metadata:
name: kedaqueueautoscaler-publisher-deployment # Deployment'in benzersiz adı
spec:
replicas: 1 # Başlangıçta çalışacak pod sayısı
selector:
matchLabels:
app: kedaqueueautoscaler-publisher # Pod'ları seçmek için kullanılan etiket
template:
metadata:
labels:
app: kedaqueueautoscaler-publisher # Pod'lara uygulanacak etiket
spec:
containers:
- name: kedaqueueautoscaler-publisher-container # Container adı
image: kedaqueueautoscaler.publisher # Kullanılacak container image
imagePullPolicy: Never # Image çekme politikası (local geliştirme için)
ports:
- containerPort: 8080 # Container'ın dinleyeceği port
resources:
requests: # Minimum kaynak gereksinimleri
cpu: "200m" # 0.2 CPU çekirdek
memory: "256Mi" # 256 MB RAM
limits: # Maksimum kaynak sınırları
cpu: "1" # 1 CPU çekirdek
memory: "512Mi" # 512 MB RAM
KedaQueueAutoScaler.Consumer.deployment.yaml;
apiVersion: apps/v1
kind: Deployment
metadata:
name: kedaqueueautoscaler-consumer-deployment # Deployment'in benzersiz adı
spec:
replicas: 3 # Başlangıçta çalışacak pod sayısı
selector:
matchLabels:
app: kedaqueueautoscaler-consumer-deployment # Pod'ları seçmek için kullanılan etiket
template:
metadata:
labels:
app: kedaqueueautoscaler-consumer-deployment # Pod'lara uygulanacak etiket
spec:
containers:
- name: kedaqueueautoscaler-consumer-container # Container adı
image: kedaqueueautoscaler.consumer # Kullanılacak container image
imagePullPolicy: Never # Image çekme politikası (local geliştirme için)
resources: # Kaynak limitleri ve istekleri
requests: # Minimum kaynak gereksinimleri
cpu: "100m" # 0.1 CPU çekirdek
memory: "128Mi" # 128 MB bellek
limits: # Maksimum kaynak limitleri
cpu: "500m" # 0.5 CPU çekirdek
memory: "256Mi" # 256 MB bellek
Burada 6. satıra göz atarsanız eğer consumer servisinin ilk etapta 3 Pod olarak ayağa kaldırılmasını yapılandırmış oluyoruz. Bu ilk etapta pek mantıklı değil. Çünkü kimi zaman kuyrukta işlenmeyi bekleyen hiç veri olmayacak, kimi zaman da 3 instance’ın kaldıramayacağı yükte ciddi veri olacak. Böyle bir durumda sabitlik hiç etkili bir davranış olmayacaktır. Haliyle bizler de KEDA ile dinamik ölçeklendirme sürecinde bu Deployment nesnesinin bu noktasına dokunacak ve ilk replica sayısını 0’a indirgeyerek, ihtiyaç olmadığı durumda hiç instance ayağa kaldırmayacak, gerekirse KEDA sayesinde dinamik ölçeklendirmeyi işte tam o yerinde gerçekleştiriyor olacağız 😉
KedaQueueAutoScaler.Publisher.service.yaml;
apiVersion: v1
kind: Service
metadata:
name: kedaqueueautoscaler-publisher-service
spec:
type: NodePort
selector:
app: kedaqueueautoscaler-publisher
ports:
- name: http
port: 80
targetPort: 8080
nodePort: 30001
Evet…
Artık Kubernetes için gerekli olan nesneleri yapılandırdığımıza göre artık bunları aşağıdaki talimatlar eşliğinde uygulayarak, ayağa kaldırabiliriz.
kubectl apply -f '.\Kubernetes Configurations\KedaQueueAutoScaler.Publisher.deployment.yaml'
kubectl apply -f '.\Kubernetes Configurations\KedaQueueAutoScaler.Consumer.deployment.yaml'
kubectl apply -f '.\Kubernetes Configurations\KedaQueueAutoScaler.Publisher.service.yaml'
Uyarı!
Eğer publisher’a http://localhost:30001/ adresinden erişemiyorsanız
kubectl port-forward svc/kedaqueueautoscaler-publisher-service 8080:80 -n defaulttalimatıyla ‘8080’ portuna yönlendirmede bulunabilir ve http://localhost:8080/ adresinden erişebilirsiniz.
Test Edelim
Şimdi küçük bir test ile Kubernetes üzerinden yoğun mesaj akışını consumer Pod’larının loglarını gerçek zamanlı inceleyerek gözlemleyelim ve bir yandan da bu akışın 3 Pod arasında nasıl balance edildiğini takip ederek, inceleyelim.
Tabi bunun için öncelikle tüm Pod’ları listeleyelim.
kubectl get pods
 Ardından bu Pod’lara uygun gerçek zamanlı log talimatlarını aşağıdaki gibi işleyelim ve http://localhost:8080/ adresine istekte bulunarak kuyruğa yoğun mesaj akışını başlatalım.
Ardından bu Pod’lara uygun gerçek zamanlı log talimatlarını aşağıdaki gibi işleyelim ve http://localhost:8080/ adresine istekte bulunarak kuyruğa yoğun mesaj akışını başlatalım.
kubectl logs kedaqueueautoscaler-consumer-deployment-bf67686f7-bpvdq -f
kubectl logs kedaqueueautoscaler-consumer-deployment-bf67686f7-dxpt9 -f
kubectl logs kedaqueueautoscaler-consumer-deployment-bf67686f7-fqk8m -f
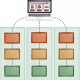
 Evet… Görüldüğü üzere Kubernetes’te uygulamamızı deploy etmiş ve 3 consumer Pod’u üzerinden kuyruğa gelen mesajları tüketebilmiş bulunmaktayız.
Evet… Görüldüğü üzere Kubernetes’te uygulamamızı deploy etmiş ve 3 consumer Pod’u üzerinden kuyruğa gelen mesajları tüketebilmiş bulunmaktayız.
Artık bu 3 Pod durumunu kuyruktaki yüke göre artırıp azaltmaya geçebilir ve KEDA ile dinamik ölçeklendirmeye odaklanabiliriz.
KEDA İle Dinamik Ölçeklendirme
İlk olarak consumer’lar için replica sayısını 0 (sıfır)’a çekerek başlayalım.
KedaQueueAutoScaler.Consumer.deployment.yaml;
apiVersion: apps/v1
kind: Deployment
metadata:
name: kedaqueueautoscaler-consumer-deployment # Deployment'in benzersiz adı
spec:
replicas: 0 # Başlangıçta çalışacak pod sayısı
selector:
matchLabels:
.
.
.
Ardından dinamik ölçeklendirme için KEDA’nın kurulumu gerekmektedir.
KEDA Kurulumu
KEDA’yı da aşağıdaki gibi Helm aracılığıyla yükleyebiliriz.
helm repo add keda https://kedacore.github.io/charts
helm repo update
helm install keda keda/keda --namespace keda --create-namespace
Yükleme işlemini tamamladıktan sonra KEDA’yı yapılandırmamız gerekmektedir.
KEDA Yapılandırması
Bu yapılandırmada KEDA’yı Secret, TriggerAuthentication ve ScaledObject olmak üzere üç açıdan yapılandırmamız gerekmektedir.
- Secret
RabbitMQ bağlantı bilgilerini güvenli bir şekilde saklamamızı sağlar.keda-rabbitmq-secret.yaml;
apiVersion: v1 kind: Secret metadata: name: keda-rabbitmq-secret stringData: connectionstring: "amqp://admin:admin@10.1.1.125:5672/"
- TriggerAuthentication
Secret’taki bilgileri ScaledObject’a güvenli bir şekilde bağlar.keda-trigger-authentication.yaml;
apiVersion: keda.sh/v1alpha1 kind: TriggerAuthentication metadata: name: keda-rabbitmq-authentication spec: secretTargetRef: - parameter: host name: keda-rabbitmq-secret key: connectionstringDikkat ederseniz 8. satırda ‘keda-rabbitmq-secret’ name değeri ile bir önceki oluşturduğumuz secret’tan connection string bilgileri çekilmektedir.
- ScaledObject
Dinamik ölçeklendirmenin tüm mantığını tanımlar. RabbitMQ trigger’ını (queue uzunluğu veya mesaj hızı) belirtir, hedef Deployment’ı ve ölçek aralıklarını (min/max replica) ayarlar. Ayrıca TriggerAuthentication’a referans verir.keda-consumer-scaledobject.yaml;
apiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: name: keda-rabbitmq-consumer-scaledobject namespace: default spec: scaleTargetRef: name: kedaqueueautoscaler-consumer-deployment # Dinamik ölçeklendirilecek Deployment'ın adı pollingInterval: 5 # n saniyede bir ölçeklendirme tetikleyicisi kontrol edilir. cooldownPeriod: 100 # Ölçeklendirme işlemi sonrası bekleme süresi (saniye cinsinden) minReplicaCount: 1 # Minimum pod sayısı maxReplicaCount: 10 # Maximum pod sayısı triggers: - type: rabbitmq metadata: queueName: "keda-queue-autoscaler-queue" # Tüketilecek RabbitMQ kuyruğunun adı queueLength: "5" # Her bir pod için hedef kuyruk uzunluğu includeUnacked: "true" # Onaylanmamış mesajları da say authenticationRef: name: keda-rabbitmq-authentication # Daha önce tanımlanmış TriggerAuthentication kaynağı adı
Bu yapılandırmalarda bulunduktan sonra aşağıdaki talimatları sırasıyla verelim.
kubectl apply -f '.\Keda Configurations\keda-rabbitmq-secret.yaml'
kubectl apply -f '.\Keda Configurations\keda-trigger-authentication.yaml'
kubectl apply -f '.\Keda Configurations\keda-consumer-scaledobject.yaml'

Test Edelim
Evet… Artık yaptığımız bu çalışmalar neticesinde RabbitMQ’daki ‘keda-queue-autoscaler-queue’ isimli kuyruğa göre dinamik ölçeklendirme gerçekleştirilmesini bekleyebiliriz. Bunu hızlıca test edebilmemiz için localhost:8080 adresine istekte bulunmamız gerekmektedir.
İstekte bulunmanın hemen ardından Pod sayısı dinamik ölçeklendirilmekte ve maksimum 10 adet olacak şekilde replikalar arttırılmaktadır. Tabi bu süreç yavaş ilerlediği için hareketli ekran görseli paylaşmaktansa, Pod’ların arttırılma sürecinden bir kesitin görselini paylaşmayı daha uygun görmekteyim. İşte, görüldüğü üzere consumer Pod’ları kuyruktaki yoğunluğa göre arttırılmaktadır. Günün sonunda tüm işlemler bitip kuyruk sıfırlandığı taktirde ScaledObject nesnesinde
İşte, görüldüğü üzere consumer Pod’ları kuyruktaki yoğunluğa göre arttırılmaktadır. Günün sonunda tüm işlemler bitip kuyruk sıfırlandığı taktirde ScaledObject nesnesinde minReplicaCount değerinde belirtildiği üzere en az 1 adet kalacak şekilde azaltılıyor olacaktır.
İşte bu kadar 🙂
Nihai olarak;
Artık aşikardır ki, modern yazılım mimarilerinde ölçeklendirme yalnızca bir tercih değil, sistemin sürdürülebilirliği ve verimliliği için vazgeçilmez bir gerekliliktir. Özellikle dinamik ölçeklendirme, hem zaman hem de maliyet açısından kritik öneme sahip senaryolarda, kaynak kullanımını akıllıca optimize eden olmazsa olmaz bir teknolojik ihtiyaca dönüşmüştür diyebiliriz. KEDA’nın sunduğu esneklik, Kubernetes üzerinde çalışan uygulamaların gerçek yük durumuna göre anlık tepki verebilmesini sağlayarak geliştiricilere ve işletmelere ciddi bir avantaj sunmaktadır. Teorideki bileşenleriyle, pratikteki konfigürasyon adımlarıyla ele aldığımız bu davranış, ölçeklenebilir mimarilere yönelik gereksinimlerin gün geçtikçe daha fazla arttığı bir dünyada, geleceğin standartlarları arasında yerini şimdiden sağlamlaştırmaktadır. Bu bağlamda, KEDA’nın yalnızca bir araç değil; modern cloud-native uygulamaların dinamik ihtiyaçlarına cevap veren stratejik bir anahtar niteliğinde davranış olduğunu vurgulamak, sanırım pekte abartı olmasa gerek.
İlgilenenlerin faydalanması dileğiyle…
Sonraki yazılarımda görüşmek üzere…
İyi çalışmalar…
Not : Örnek çalışmaya aşağıdaki GitHub adresinden erişebilirsiniz.
https://github.com/gncyyldz/Keda_Queue_AutoScaler