RAG(Retrieval-Augmented Generation) Nedir? Nasıl Uygulanır? Detaylıca İnceleyelim…
Merhaba,
Bu içeriğimizde, AI modellerini durağan eğitim verilerinin ötesine taşıyarak, güncel verilere erişmesini sağlayan RAG (Retrieval-Augmented Generation) davranışını mercek altına alacak ve nedir, ne değildir tam teferruatlı bir değerlendirmede bulunuyor olacağız.
RAG(Retrieval-Augmented Generation) Nedir?
RAG; bir LLM’in, gelen soruya cevap vermeden önce, kendi ezberiyle cevap vermesi yerine, harici ve güvenilir bir bilgi/veri kaynağından(PDF’ler, veri tabanları, web sayfaları vs.) ilgili bilgileri bulup, bu bilgiler ışığında cevap üretmesi davranışıdır.
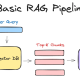
RAG’ın akış mantığı oldukça basittir:
🔄 RAG Akış Mantığı
Kullanıcı bir soru sorar.
Sistem, şirket içi belgelerinizde veya güncel verilerde bu soruyla ilgili parçaları arar.
Bulunan bu ham bilgiler, kullanıcının sorusuyla birleştirilir.
LLM, önüne koyulan bu spesifik belgelere bakarak doğru ve güncel bir cevap yazar.
RAG, Ne Kadar Kritik Bir Davranıştır?
Kurumsal ve ciddi sistemlerde RAG yoksa, sistem yok diyebiliriz.
RAG, kurumsal yapay zeka projeleri için hayati (mission-critical) öneme sahiptir. Bir model ne kadar gelişmiş olursa olsun (GPT-4, Claude 3.5 vb.), eğitildiği tarih itibarıyla bilgi seti donacaktır. Haliyle RAG ile bu donmuş bilgi setine canlılık kazandırılabilmektedir.
Bu açıdan bakıldığında; kurumsal chatbot’larda, iç doküman sorgulamalarda, mevzuat / hukuk / prosedür içeriklerinin analizinde, teknik destek botlarında ve agent tabanlı gelişmiş sistemlerde RAG, opsiyonel bir eklentiden ziyade, bilgi açısından güvenilirlik için zorunlu bir reflekstir.
RAG’sız LLM, güzel konuşan ama sorumluluk almayan biri gibi davranır.
RAG olmasa ne olurdu?
Model bilmediği bir konuda -bilmiyorum- demek yerine, halüsinasyona uğrayarak mantıklı görünen ama tamamen yanlış bilgiler uydurabilir. RAG bu tarz emin olunmayan yerlerdeki verilen cevaplarda, -Bu bilgiyi nereden aldın?- sorusuna gösterebileceği referansı olacağı için tutarlılık sağlanabilmektedir.
Bunun dışında LLM, bilgi eskimesinden dolayı şirketinizin dünkü satış verilerini veya yeni yayınlanan bir yönetmeliği asla bilemez. RAG ile kuruma özel bilgi sürece dahil edilip; LLM’e şirket hafızası kazandırılabilir, anlık ve güncel bilgi ile konuşması sağlanabilir.
Tüm bunların dışında, tüm verilerinizi modele en baştan öğretmek (fine-tuning) hem çok pahalı olacaktır hem de verinin güncelliği değiştikçe kontrolü zorlaşacak, verisel açıdan karanlık bir alan oluşacaktır. İşte bu tarz duruma karşında RAG, güvenlik riskini olabildiğince minimize etmektedir.
RAG’ın Çözdüğü Gerçek Sorunlar Nelerdir?
Bunu aşağıdaki gibi bir kaç başlık altında, sahada karşılaşılan sorunlar eşliğinde örneklendirerek toparlayabiliriz;
- Güncellik
Misal olarak RAG; -Bugün yürürlüğe giren yeni vergi kanunu nedir?- sorusuna yanıt verebilmeyi sağlar. - Özel Veri Erişimi
Şirketinize özel, gizli ve internette bulunmayan dokümanlar üzerinden soru-cevap yapılmasını sağlar. - Kaynak Gösterme
RAG sistemleri, cevabı hangi dokümanın hangi sayfasından aldığına kadar detaylı referans verebilmektedir. Bu da güvenilirlik açısından oldukça önemlidir.Ayrıca LLM’den her şeyi bilmesini beklemek gereksizdir. Nereden bakacağını bilmesi bizler için daha tercih edilebilirdir.
- Düşük Maliyet
Modeli yeniden eğitmek yerine, sadece bir veri tabanını güncellemek binlerce kat daha ucuz ve az maliyetlidir.
Üretilen Netice LLM Bünyesine Alınır mı?
Hayır. RAG ile üretilen netice LLM’in bünyesine (yani parametrelerine) alınmaz. Ancak bu sistemin asla öğrenemeyeceği anlamına da gelmiyor. Şöyle ki, öncelikle -LLM bünyesine alınmaktan- kastedilen nedir bunu öncelikle anlayalım, ardından sistemin öğrenmesi kavramıyla arasındaki ince ayrımı ortaya koymaya çalışalım.
“LLM bünyesine alınmak” ne demek?
Bir bilginin LLM bünyesine alınması demek; modelin ağırlıklarının (weights) değişmesi, yani fine-tuning / training yapılması demektir. Böylece model kapatılıp açıldığında bile o bilginin kalıcı olarak hatırlanması sağlanmış olacaktır. Evet, RAG’da bunların hiçbiri söz konusu değildir.
RAG’de; model öğrenmez, ağırlıklar değişmez, kalıcı hafıza oluşmaz ve sonraki konuşmada üretilen neticeler otomatik olarak hatırlanmaz! Sadece o anki cevap, dış kaynağa dayanır ve geçici bir bağlam üzerinden model, sanki önceden bu bilgiyi biliyormuş gibi cevap üretir.
RAG, modele okuyarak cevap üretmeyi sağlarken; Fine-tuning ise ezberleyerek cevap üretmeyi öğrenmesini sağlar.
Peki üretilen sonuçlar tamamen çöpe mi gidiyor?
Tabi ki de hayır! Sonuçta üretilen veriler LLM’e olmasa da sisteme kazandırılıyor. Ne mi yapılıyor? Üretilen ve doğrulanan veri dokümana dönüştürülüyor, embedding alınıyor ve vector store’a yazılıyor. Bir sonraki soruda ise eğer ihtiyaç varsa tekrar çekilebiliyor. Yani böylece model olmasa da sistem öğreniyor! Bu anlayış, konu bağlamında oldukça kritiktir!
Ha üretilen cevabı model görüyor mu? diye sorarsanız… evet, görüyor! Ancak malumunuz; görmek, öğrenmek demek değildir! LLM, prompt içerisindeki her şeyi geçici bağlam olarak gördüğü için context window kapanınca her şey unutuluyor!
Ayrıca şuna da dikkatinizi çekmek isterim ki, RAG sonucu elde edilen veriler tam doğrulanmadan LLM’e yazılması da pek doğru olmayacaktır. Ne de olsa RAG çıktısı; yanlış olabilir, bağlama özel olabilir ya da zamana bağlı olabilir. Bu tarz olası durumlara sahip verileri LLM’e gömmek demek modeli kalıcı olarak kirletmek demektir. Eğer ki eldeki veri sabit, evrensel ve değişmeyecek bilgiyse işte o taktirde LLM bünyesine aktarılma kaygısı güdülmelidir.
Bu açıdan bakıldığında sistemlerimizi tasarlarken doğru mimari bizlere göz kırpmakta ve bilgiyi dışardan alan LLM modellemesi karşımıza çıkmaktadır. Evet, sistemin aklı LLM’de değil AI Agent’ta olmalıdır. LLM oldukça saf kalmalı ve prompt’a karşılık veri üretimiyle ilgilenmelidir. AI Agent ise tüm sürecin kararını ve stratejisini yürütmelidir. İdeal olan sistem böyledir…
RAG’ın MCP İle Alakası Var mı?
RAG ile MCP aynı şey olmasa da akraba iki teknolojidir diyebiliriz. MCP, LLM’e dış dünyayı standart bir şekilde açan protokoldür. Yani MCP, LLM’in dışarıdan nasıl besleneceğinin protokolvari cevabıdır.
Şöyle düşünülebilir… RAG’da, orkestrasyon katmanı olan AI Agent; ne zaman, hangi bilgiyi alacağını sorarken; MCP’de ise yine orkestrasyon katmanı bu bilgiyi LLM’e nasıl vereceğini sormaktadır. Yani RAG bir davranış ve stratejiyken, MCP ise taşıma ve entegrasyon standardıdır diyebiliriz.
MCP olmadan RAG olur mu?
Evet, zaten bu güne kadar yapılan RAG’ların %90’ı zaten MCP’sizdi. Ancak MCP ile yapılan RAG’larda bir standartlaşma söz konusu olmakta ve her tool için ayrı prompt yazma derdi sona ermektedir. Ancak unutulmaması gereken nokta şudur ki, MCP RAG’ı garanti etmemektedir.
Microsoft Agent Framework ile RAG Yapılabilir mi?
Evet, hem de modelden bağımsız bir şekilde… Çünkü RAG; model değil, bir orkestrasyon problemidir.
RAG, LLM’in değil, AI Agent’ın sorumluluğun da bir davranıştır.
İster Azure OpenAI üzerinden GPT modellerini kullanın, ister lokalde çalışan bir Llama modelini… fark etmeksizin herhangi bir LLM ile Microsoft Agent Framework aracılığıyla bu modellere bir RAG Tool tanımlanabilmektedir.
Çalışma mantığı oldukça basittir; AI Agent’a şu yeteneğin verilmesi yeterlidir: -Eğer cevabı bilmiyorsan, şu veri tabanına git ve ara- Bu yönlendirmeden sonra AI Agent, gerektiği taktirde belirlenen PDF veya SQL kaynağından veriyi çekecek ve yanıtı ona göre şekillendirecektir.
RAG yapmak için modelin kendisini değiştirmenize gerek yoktur! Yalnızca modelin önüne bir -veri getirme mekanizması- eklenmesi yeterli olacaktır.
Örnek Çalışma
Microsoft Agent Framework ile aşağıdaki gibi bir Vector Search çalışmasını ele alarak RAG davranışını örneklendirebiliriz.
İlk olarak çalışmanın sade halini aşağıya alalım:
public class EmbeddingService
{
//Embedding işlemleri için standart bir arayüzdür.
//string verilen input'u, Embedding<float> türünden output etmektedir.
private readonly IEmbeddingGenerator<string, Embedding<float>> _embeddingGenerator;
public EmbeddingService(string key, string model = "text-embedding-3-small", string endpoint = "https://openrouter.ai/api/v1")
{
//OpenAI için EmbeddingClient oluşturuluyoruz.
var embeddingClient = new EmbeddingClient(
model: model,
credential: new System.ClientModel.ApiKeyCredential(key: key),
options: new OpenAIClientOptions
{
Endpoint = new Uri(endpoint)
}
);
//Ve bu EmbeddingClient'ı IEmbeddingGenerator'a dönüştürerek provider'dan bağımsız kod yazılabilir hale geliyoruz.
_embeddingGenerator = embeddingClient.AsIEmbeddingGenerator();
}
// Tek bir metni embedding eden metottur.
public async Task<float[]> GenerateEmbeddingAsync(string text)
{
var result = await _embeddingGenerator.GenerateAsync(text);
return result.Vector.ToArray();
}
//Daha hızlı bir embedding işlemi sağlayan metottur.
public async Task<ReadOnlyMemory<float>> GenerateVectorAsync(string text)
{
return await _embeddingGenerator.GenerateVectorAsync(text);
}
public async Task<List<float[]>> GenerateEmbeddingsAsync(IEnumerable<string> texts)
{
var results = await _embeddingGenerator.GenerateAsync(texts);
return results
.Select(embedding => embedding.Vector.ToArray())
.ToList();
}
//İki vektör arasındaki cosine similarity'i hesaplar.
//Değer -1 ile 1 arasında olacaktır. 1 = tatamen benzer, 0 = ilişkisiz, -1 = zıt
public double CalculateCosineSimilarity(float[] vectors1, float[] vectors2)
{
//Vektör boyutları eşit olmalı
if (vectors1.Length != vectors2.Length)
throw new ArgumentException("Vektör boyutları eşleşmiyor!");
//Dot product : İki vektörün nokta çarpımı
//Σ(a[i] * b[i])
double dotProduct = 0;
//Magnitude (büyüklük) hesaplamaları
// ||a|| = √(Σ(a[i]²))
double mag1 = 0, mag2 = 0;
//Tüm boyutlar için hesaplama
for (int i = 0; i < vectors1.Length; i++)
{
dotProduct += vectors1[i] * vectors2[i]; // a[i] * b[i]
mag1 += vectors1[i] * vectors1[i]; // a[i]²
mag2 += vectors2[i] * vectors2[i]; // b[i]²
}
//Magnitude'ların karakökünü alma
mag1 = Math.Sqrt(mag1);
mag2 = Math.Sqrt(mag2);
//Sıfır vektör kontrolü
if (mag1 == 0 || mag2 == 0)
return 0;
//Cosine similarity formülü: (a · b) / (||a|| * ||b||)
return dotProduct / (mag1 * mag2);
}
}
Burada ilk olarak vector search sürecinde embedding sorumluluğunu üstlenen sınıfımızı görüyoruz. Bu sınıf içerisindeki IEmbeddingGenerator arayüzü sayesinde OpenAI, Azure OpenAI, Ollama, HuggingFace vs. gibi provider’lardan bağımsız bir şekilde embedding süreçleri yürütülebilmekte ve EmbeddingClient sınıfı sayesinde de ilgili provider’ın embedding endpoint’i ile iletişime geçilebilmektedir. Süreçte text-embedding-3-small modeli eşliğinde embedding sürecinin seyrettiğini, ayrıca dikkat ederseniz; GenerateAsync metodu ile embedding işlemlerinin yürütüldüğünü, bir yandan da GenerateVectorAsync metoduyla daha az maliyetli embedding sürecinin de desteklendiğini göreceksiniz.
Şimdi de embedding edilmiş verilerin, veritabanı işlemlerinin ve gerekli vector search çalışmalarının sorumluluğunu üstlenecek veritabanı sınıfını ele alalım:
public class SqlVectorStoreService
{
private readonly string _connectionString;
public SqlVectorStoreService(string connectionString = "Server=localhost,1433;Database=ExampleDB;User Id=sa;Password=Test123!;TrustServerCertificate=True;")
{
_connectionString = connectionString;
}
public async Task InitializeDatabaseAsync()
{
using var connection = new SqlConnection(_connectionString);
await connection.OpenAsync();
var createTableSql = $@"
IF NOT EXISTS (SELECT * FROM sys.tables WHERE name = 'Embeddings')
BEGIN
CREATE TABLE Embeddings (
Id INT IDENTITY(1,1) PRIMARY KEY,
Text NVARCHAR(MAX) NOT NULL,
EmbeddingVector VECTOR(1536) NOT NULL,
Metadata NVARCHAR(MAX) NULL,
CreatedAt DATETIME2 DEFAULT GETDATE()
);
END";
using var command = new SqlCommand(createTableSql, connection);
await command.ExecuteNonQueryAsync();
}
public async Task SaveEmbeddingAsync(string text, double[] embedding, string? metadata = null)
{
using var connection = new SqlConnection(_connectionString);
await connection.OpenAsync();
//Double array'i byte array'e çeviriyoruz.
var embeddingBytes = new byte[embedding.Length * sizeof(double)];
Buffer.BlockCopy(embedding, 0, embeddingBytes, 0, embeddingBytes.Length);
var insertSql = $@"
INSERT INTO Embeddings (Text, EmbeddingVector, Metadata)
VALUES (@Text, @Embedding, @Metadata)";
using var command = new SqlCommand(insertSql, connection);
command.Parameters.AddWithValue("@Text", text);
command.Parameters.AddWithValue("@Embedding", embeddingBytes);
command.Parameters.AddWithValue("@Metadata", metadata ?? (object)DBNull.Value);
await command.ExecuteNonQueryAsync();
}
public async Task SaveEmbeddingsBatchAsync(List<(string text, float[] embedding, string metadata)> items)
{
using var connection = new SqlConnection(_connectionString);
await connection.OpenAsync();
using var transaction = connection.BeginTransaction();
try
{
foreach (var (text, embedding, metadata) in items)
{
var embeddingBytes = new byte[embedding.Length * sizeof(float)];
Buffer.BlockCopy(embedding, 0, embeddingBytes, 0, embeddingBytes.Length);
var insertSql = $@"
INSERT INTO Embeddings (Text, EmbeddingVector, Metadata)
VALUES (@Text, @Embedding, @Metadata)";
using var command = new SqlCommand(insertSql, connection, transaction);
command.Parameters.AddWithValue("@Text", text);
command.Parameters.AddWithValue("@Metadata", metadata ?? (object)DBNull.Value);
var sqlVector = new SqlVector<float>(embedding);
command.Parameters.Add(new SqlParameter
{
ParameterName = "@Embedding",
Value = sqlVector,
SqlDbType = System.Data.SqlDbType.Vector
});
await command.ExecuteNonQueryAsync();
}
await transaction.CommitAsync();
}
catch (Exception ex)
{
await transaction.RollbackAsync();
throw new Exception($"Toplu kayıt hatası : {ex.Message}", ex);
}
}
public async Task<List<SearchResult>> SearchAsync(float[] queryEmbedding, EmbeddingService embeddingService, int topK = 5, double minSimilarity = 0.0)
{
using var connection = new SqlConnection(_connectionString);
await connection.OpenAsync();
var selectSql = "SELECT Id, Text, EmbeddingVector, Metadata, CreatedAt FROM Embeddings";
using var command = new SqlCommand(selectSql, connection);
using var reader = await command.ExecuteReaderAsync();
var results = new List<SearchResult>();
while (await reader.ReadAsync())
{
var id = reader.GetInt32(0);
var text = reader.GetString(1);
var embeddingBytes = (byte[])reader.GetValue(2);
var metadata = reader.IsDBNull(3) ? null : reader.GetString(3);
var createdAt = reader.GetDateTime(4);
var embedding = new float[embeddingBytes.Length / sizeof(float)];
Buffer.BlockCopy(embeddingBytes, 0, embedding, 0, embeddingBytes.Length);
var similarity = embeddingService.CalculateCosineSimilarity(queryEmbedding, embedding);
if (similarity >= minSimilarity)
{
results.Add(new()
{
Id = id,
Text = text,
CreatedAt = createdAt,
Metadata = metadata,
Similarity = similarity
});
}
}
return results
.OrderByDescending(r => r.Similarity)
.Take(topK)
.ToList();
}
public async Task ClearAllAsync()
{
using var connection = new SqlConnection(_connectionString);
await connection.OpenAsync();
var deleteSql = "TRUNCATE TABLE Embeddings";
using var command = new SqlCommand(deleteSql, connection);
await command.ExecuteNonQueryAsync();
}
public async Task<int> GetCountAsync()
{
using var connection = new SqlConnection(_connectionString);
await connection.OpenAsync();
var countSql = "SELECT COUNT(*) FROM Embeddings";
using var command = new SqlCommand(countSql, connection);
return (int)(await command.ExecuteScalarAsync());
}
public async Task<List<SearchResult>> VectorSearchAsync(float[] queryEmbedding, int topK = 5, double minSimilarity = 0.0)
{
using var connection = new SqlConnection(_connectionString);
await connection.OpenAsync();
var selectSql = @"
SELECT TOP (@TopK)
Id,
Text,
EmbeddingVector,
Metadata,
CreatedAt,
-- Cosine similarity hesapla: 1 - cosine distance
(1.0 - VECTOR_DISTANCE('cosine', EmbeddingVector, @QueryVector)) AS Similarity
FROM Embeddings
WHERE (1.0 - VECTOR_DISTANCE('cosine', EmbeddingVector, @QueryVector)) >= @MinSimilarity
ORDER BY VECTOR_DISTANCE('cosine', EmbeddingVector, @QueryVector) ASC";
using var command = new SqlCommand(selectSql, connection);
command.Parameters.AddWithValue("@TopK", topK);
command.Parameters.AddWithValue("@MinSimilarity", minSimilarity);
var queryVector = new SqlVector<float>(queryEmbedding);
command.Parameters.Add(new SqlParameter
{
ParameterName = "@QueryVector",
Value = queryVector,
SqlDbType = System.Data.SqlDbType.Vector
});
using var reader = await command.ExecuteReaderAsync();
var results = new List<SearchResult>();
while (await reader.ReadAsync())
{
var id = reader.GetInt32(0);
var text = reader.GetString(1);
// EmbeddingVector'u okumaya gerek yok (zaten similarity hesaplandı)
var metadata = reader.IsDBNull(3) ? null : reader.GetString(3);
var createdAt = reader.GetDateTime(4);
var similarity = reader.GetDouble(5); // SQL Server'da hesaplanan similarity
// Sonuç listesine ekle
results.Add(new SearchResult
{
Id = id,
Text = text,
Similarity = similarity,
Metadata = metadata,
CreatedAt = createdAt
});
}
return results;
}
}
Burada klasik veritabanı işlemlerinin yanında esas olarak VectorSearchAsync metodu içerisinde vector search çalışması gerçekleştirilmekte ve SQL Server 2025 ile gelen VECTOR_DISTANCE fonksiyonu sayesinde cosine similarity hesaplanarak gerekli sorgulama gerçekleştirilmektedir.
Ve son olarak da bu çalışmanın precompute embeddings ve semantic search işlemlerinin yürütüldüğü ana endpoint’lerini inceleyelim:
app.MapGet("/precompute", async () =>
{
EmbeddingService embeddingService = new();
var vectorStore = new SqlVectorStoreService();
await vectorStore.InitializeDatabaseAsync();
var documents = new List<string>
{
"Yapay zeka, insan zekasını taklit eden bilgisayar sistemleridir.",
"Machine learning, yapay zekanın önemli bir alt dalıdır.",
"Derin öğrenme, sinir ağları kullanarak çalışır ve karmaşık desenleri öğrenir.",
"Python, veri bilimi ve makine öğrenmesi için en popüler programlama dilidir.",
"SQL Server, Microsoft'un güçlü ilişkisel veritabanı yönetim sistemidir.",
"C# ile .NET Framework kullanarak güvenli ve ölçeklenebilir uygulamalar geliştirebilirsiniz.",
"Hugging Face, doğal dil işleme modelleri için en büyük platformdur.",
"Embedding vektörleri, metinlerin anlamını sayısal olarak temsil eder.",
"Cosine similarity, iki vektör arasındaki açıyı ölçerek benzerlik hesaplar.",
"Semantic search, anlam bazlı arama yaparak daha ilgili sonuçlar bulur.",
"ONNX, makine öğrenmesi modellerini farklı platformlarda çalıştırmak için açık formattır.",
"all-MiniLM-L6-v2, 384 boyutlu embedding vektörleri üreten hafif bir modeldir."
};
var embeddings = await embeddingService.GenerateEmbeddingsAsync(documents);
var batch = documents
.Zip(embeddings, (text, emb) => (text, emb, metadata: (string)null))
.ToList();
await vectorStore.SaveEmbeddingsBatchAsync(batch!);
});
app.MapGet("/semantic-search/{text?}", async (string? text) =>
{
EmbeddingService embeddingService = new();
var vectorStore = new SqlVectorStoreService();
if (text is not null)
{
var embedded = await embeddingService.GenerateEmbeddingAsync(text!);
var results = await vectorStore.VectorSearchAsync(embedded);
return TypedResults.Json(results.ToList());
}
return null;
});
Evet… Şimdi bu en yalın haliyle ele aldığımız çalışma üzerinden RAG davranışını sergilemeye başlayabiliriz.
Bunun için aşağıdaki gibi iki adet endpoint geliştirmemiz yeterli olacaktır;
Basit yanıt üretimi için:
// RAG sorgu endpoint'i - Basit yanıt üretimi için
app.MapGet("/ask/{question?}", async (string? question, EmbeddingService embeddingService, SqlVectorStoreService sqlVectorStoreService, [FromKeyedServices("ragAgent")] AIAgent ragAgent) =>
{
int topK = 3;
double minSimilarity = 0.3;
try
{
//Kullanıcının sorusunu embedding'e çeviriyoruz.
var queryEmbedding = await embeddingService.GenerateVectorAsync(question!);
//Vector store'dan en benzer içerikleri getirtiyoruz.
var searchResults = await sqlVectorStoreService.VectorSearchAsync(queryEmbedding.ToArray(), topK, minSimilarity);
if (searchResults is [])
return Results.Ok(new
{
question,
answer = "Üzgünüm, bu soruyla ilgili bilgi bulunamadı.",
sources = new int[] { }
});
StringBuilder context = new();
context.AppendLine("İlgili dokümanlar :");
context.AppendLine();
for (int i = 0; i < searchResults.Count; i++)
{
context.AppendLine($"[Doküman {i + 1}] (Benzerlik :{searchResults[i].Similarity:F3})");
context.AppendLine(searchResults[i].Text);
context.AppendLine();
}
var ragPrompt = $@"
Context bilgileri : {context}
Kullanıcı sorusu : {question}
Lütfen yukarıdaki context bilgilerine dayanarak kullanıcının sorusunu yanıtla.
Ayrıca cevabında hangi dokümanları kullandığını belirt.";
var response = await ragAgent.RunAsync(ragPrompt);
return Results.Ok(new
{
question,
answer = response.Text,
sources = searchResults.Select(r => new
{
r.Text,
similarity = Math.Round(r.Similarity, 3),
id = r.Id
}).ToList()
});
}
catch (Exception ex)
{
return Results.BadRequest(new { error = ex.Message });
}
});
Detaylı yanıt üretimi için:
// RAG sorgu endpoint'i - Detaylı yanıt üretimi için
app.MapPost("/ask", async (RagQueryRequest request, EmbeddingService embeddingService, SqlVectorStoreService sqlVectorStoreService, [FromKeyedServices("ragAgent")] AIAgent ragAgent) =>
{
try
{
//Kullanıcının sorusunu embedding'e çeviriyoruz.
var queryEmbedding = await embeddingService.GenerateVectorAsync(request.Question!);
//Vector store'dan en benzer içerikleri getirtiyoruz.
var searchResults = await sqlVectorStoreService.VectorSearchAsync(queryEmbedding.ToArray(), request.TopK ?? 3, request.MinSimilarity ?? 0.3d);
if (searchResults is [])
return Results.Ok(new RagQueryResponse
{
Question = request.Question,
Answer = "Üzgünüm, bu soruyla ilgili bilgi bulunamadı. Lütfen sorunuzu farklı şekilde ifade etmeyi deneyiniz.",
Sources = [],
SourceCount = 0
});
StringBuilder context = new();
context.AppendLine("İlgili dokümanlar :");
context.AppendLine();
for (int i = 0; i < searchResults.Count; i++)
{
context.AppendLine($"[Doküman {i + 1}] (Benzerlik :{searchResults[i].Similarity:F3})");
context.AppendLine(searchResults[i].Text);
context.AppendLine();
}
var systemPrompt = request.CustomSystemPrompt ?? $@"
Sen bir RAG asistanısın. Görevin:
1. Sağlanan kaynak ve dokümanları dikkatlice analiz et
2. Kullanıcının sorusuna YALNIZCA bu kaynaklara dayanarak cevap ver
3. Cevabında hangi kaynağı kullandığını [Kaynak-X] ya da [Doküman-X] şeklinde belirt
4. Eğer kaynaklarda cevap yoksa, bunu açıkça söyle
5. Kendi bilgilerinle tahmin yapma, sadece verilen bilgileri kullan";
var userPrompt = $@"
Context bilgileri : {context}
Kullanıcı sorusu : {request.Question}
Lütfen yukarıdaki kaynak ve dokümanlara dayanarak kullanıcının sorusunu yanıtla.
Ayrıca cevabında hangi dokümanları kullandığını belirt.";
var messages = new List<OpenAI.Chat.ChatMessage>
{
OpenAI.Chat.ChatMessage.CreateSystemMessage(systemPrompt),
OpenAI.Chat.ChatMessage.CreateUserMessage(userPrompt)
};
var chatResponse = await ragAgent.RunAsync(messages);
var contentList = chatResponse.Content.OfType<ChatMessageContentPart>();
var response = new RagQueryResponse
{
Question = request.Question,
Answer = string.Join("", contentList.Select(item => item.Text)) ?? "Yanıt oluşturulmadı!",
Sources = searchResults.Select((r, index) => new SourceInfo
{
Id = r.Id,
Text = r.Text,
Similarity = r.Similarity,
Rank = index + 1,
Metadata = r.Metadata
}).ToList(),
SourceCount = searchResults.Count
};
return Results.Ok(response);
}
catch (Exception ex)
{
return Results.BadRequest(new { error = ex.Message, stackTrace = ex.StackTrace });
}
});
Her iki endpoint’e de göz atarsanız eğer kullanıcıdan gelen soru LLM’e gönderilmeden önce semantic search ile konuyla ilgili dokümanlar taranmakta ve similarity’si yüksek olan ilk veriler elde edilerek prompt’a aktarılmaktadır. Böylece LLM’in kendi eğitim verisi dışında kalan bilgiler, anlamsal arama yoluyla harici veri kaynaklarından elde edilerek modele verilmekte ve böylece belirli bir çerçevede cevap üretmesi gerektiği söylemektedir…
Bu minvalde detaylı yanıt üretimi gerçekleştiren endpoint’in test neticesini aşağıdaki görselden inceleyebilir ve LLM’i RAG davranışı neticesinde nasıl özelleştirebildiğimizi değerlendirebilirsiniz:
İşte bu kadar 🙂
Nihai olarak;
RAG davranışının, büyük dil modellerini “her şeyi ezberlemiş bilge” olmaktan çıkarıp, “güvenilir kaynaklara hızlıca bakabilen, güncel ve sorumlu bir danışman” haline getiren oldukça etkili ve ekonomik bir yaklaşım olduğunun ve modern kurumsal yapay zeka mimarilerinin omurgasının artık RAG’sız düşünülemeyeceğinin farkına vardığımızı söyleyebilir ve içeriğimizi burada noktayabiliriz…
İlgilenenlerin faydalanması dileğiyle…
Sonraki yazılarımda görüşmek üzere…
İyi çalışmalar…
Not : Örnek çalışmaya aşağıdaki GitHub adresinden erişebilirsiniz.
https://github.com/gncyyldz/Microsoft.Agent.Framework.RAG.Example





















Enfes bir yazı olmuş hocam, ellerinize sağlık.